Keeping track of the bad things: StackExchange.Exceptional
The best part of working for Stack Exchange is that our code, network and databases are so awesome that we never throw exceptions.
Okay, okay, back to reality. Everyone has exceptions, so how do we handle the first step of recording them? Most .Net developers have heard of ELMAH (Error Logging Modules and Handlers), and Stack Exchange started out using a modified version of this for over a year. The setup was simple: we were using the XML file store pointing to a share on one of the web servers (due to most of the problems being SQL or network related when shit hit the fan). What this setup didn’t allow for was high-traffic logging, since the 200 file loop necessitated a directory file listing (not so fast in windows), reading existing files to see if it was a duplicate, then updating the duplicate with a new count if one was found. Take into account the level of traffic Stack Overflow gets at any point in the day and all this meant was we effectively took that web server out of rotation (due to pegging it’s network throughput just logging the errors…yes, we saw the humor there).
When I finally got some time to stick the errors into SQL in a way that fit our needs, I wrote StackExchange.Exceptional (with input from all our dev teams along the way). It certainly borrows a fundamental idea from ELMAH (multiple stores on a single error interface mainly), but after that they diverge significantly. We needed a few things that no existing error handler put in one package:
- High speed logging (upwards of 100,000 exceptions/minute)
- Error roll-ups (for similar exceptions, showing a duplicate count that increases rather than logging a separate entry)
- Handling the case where we can’t reach the central error store (e.g. the connection to SQL is interrupted)
- Custom data for our exceptions
- Querying relevant exception data
All but the last one went into StackExchange.Exceptional directly, the last one factors into a bigger picture coming soon.
Let me explain why we need the above. The high volume one’s pretty easy; we get a lot of traffic on Stack Overflow alone. When shit hits the fan, the exceptions roll in pretty fast. For example when redis goes offline or SQL server is unreachable we’re throwing 10,000 errors in under a few seconds. While we’re throwing lots of errors, they’re not likely to tell us much in all that repetition. 10,000 of the same exception helps us no more in debugging than that error logged once with a x10,000 beside it…so that’s what Exceptional does. If an error has the same stack trace then we just increase a duplicate counter on the SQL row, instead of logging another row.
When we’re throwing exceptions due to a network issue, guess what trying to log over the network does. Yeah, this one’s not hard to see coming, so what Exceptional does is keep a memory-based exception store that queues up to 1000 exceptions (duplicates roll up in that 1000) when it’s unable to write whatever remote store you’ve configured (SQL or JSON). It will retry writing the exceptions every 2 seconds. Once successful, things go back to normal and exceptions are logged as they come in. If there is currently a problem connecting to the error store, the issue will be shown in the exceptions list.
The last two are probably less relevant. Custom data just enables storing of string name/value pairs with the exception for display only or use via JavaScript includes on the exception views. I’ll cover this in detail on the project page in a specific wiki, for now the quick bits are in the setup wiki. Querying is not really covered in Exceptional, it just has a SQL structure that’s friendly for doing so (relevant bits of exceptions broken out into individual columns). The actual searching is something we have, but I have to do a bit more unexpected work to get that dashboard out the door. There are other benefits this netted us, but they’re hard to explain without a full dashboard post when that’s released…I’ll try and do so as quickly as I can figure out the open-source charting story.
I’ve added a few initial wikis to github for getting Exceptional up and running, I’ll try and get an example project up as well…in the next few days as time allows. Here’s a quick view of the list/detail screens to get a feel:
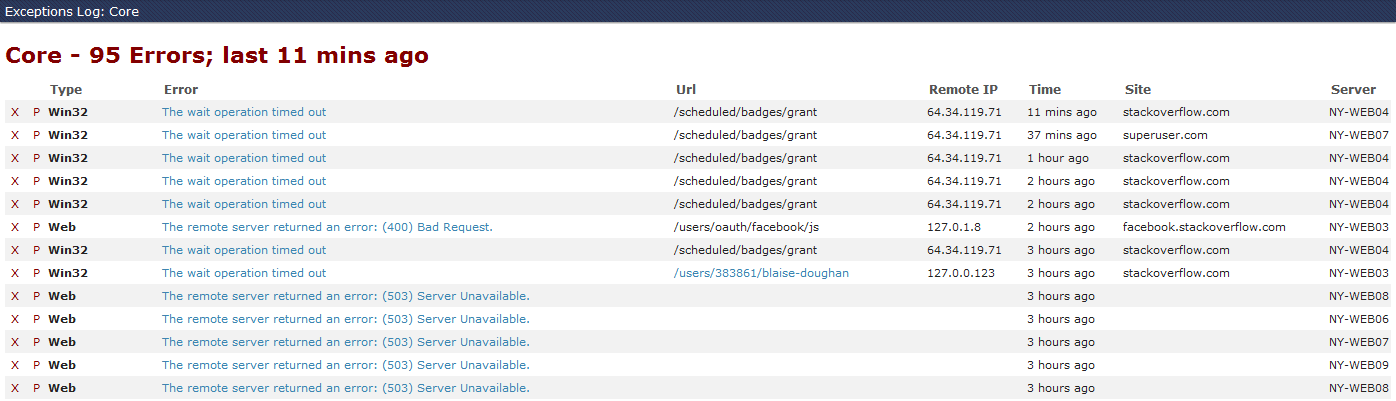
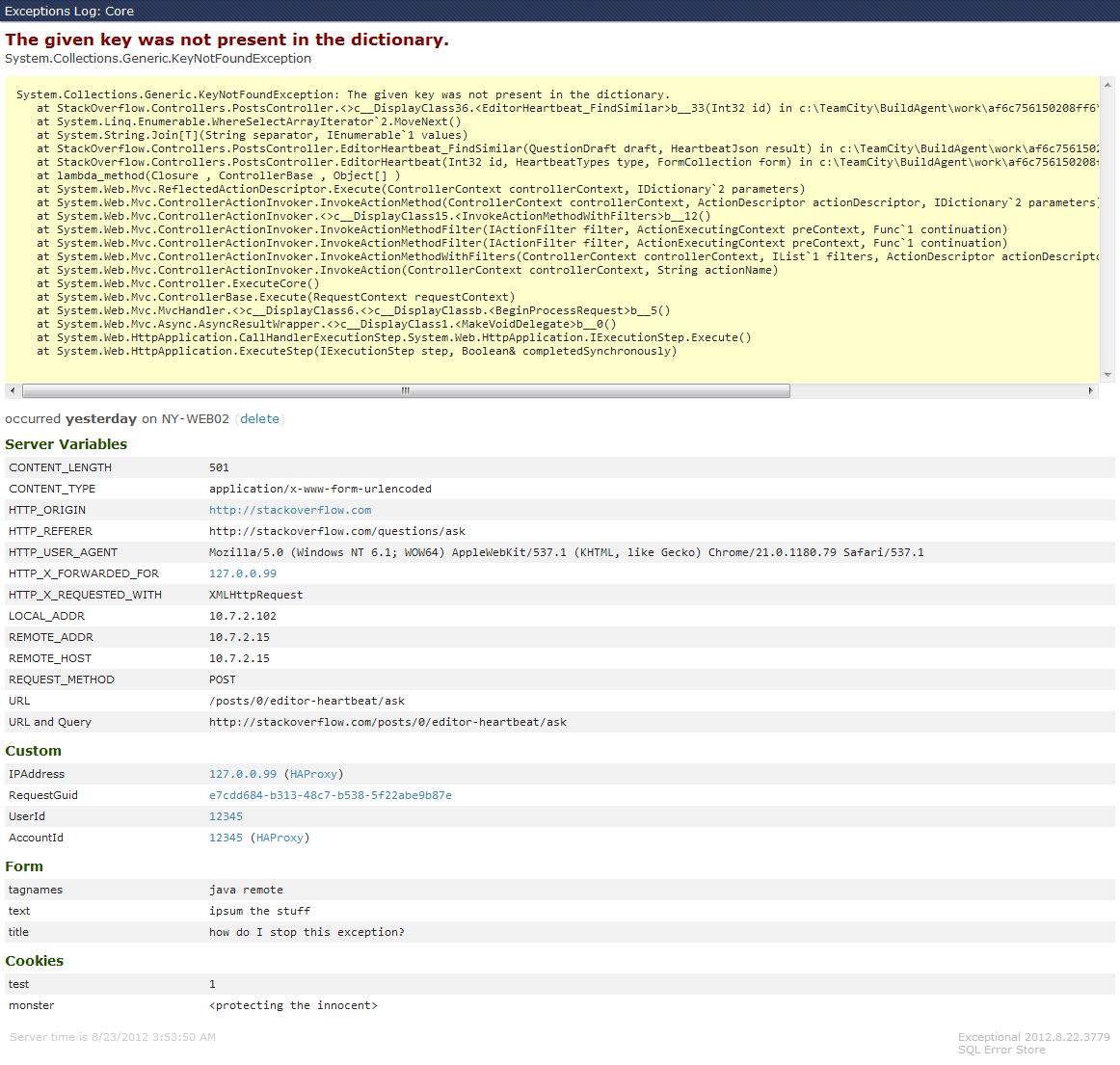
Update: A sample project is now posted alongside Exceptional core on github. Some additional store providers (e.g. MongoDB) have already been requested, stay tuned for those - they’ll show up in the form of other packages with a dependency on StackExchange.Exceptional, so if you don’t want that store’s driver, you won’t have to include it.