Stackoverflow.com: the road to SSL
A question we often get asked at Stack Exchange is why stackoverflow.com and all our other domains aren’t served over SSL. It’s a user request we see at least a few times a month asking to ensure their security and privacy. So why haven’t we done it yet? I wanted to address that here, it’s not that we don’t want to do it, it’s just a lot of work and we’re getting there.
So, what’s needed to move our network to SSL? Let’s make a quick list:
- Third party content must support SSL:
- Ads
- Avatars
- Google Analytics
- Inline Images & Videos
- MathJax
- Quantcast
- Our side has to support SSL:
- Our CDN
- Our load balancers
- The sites themselves
- Websockets
- Certificates (this one gets interesting)
Ok, so that doesn’t look so hard, what’s the big deal? Let’s look at third party content first. Note that with all of these items, they’re totally outside our control. All we can do is ask for them to support SSL…but luckily we work with awesome people that are they’re helping us out.
Now here’s where stuff gets fun, we have to support SSL on our side. Let’s cover the easy parts first. Our CDN has to support SSL. Okay, it’s not cheap but it’s a problem we can buy away. We only use cdn.sstatic.net for production content so a cdn.sstatic.net & *.cdn.sstatic.net combo cert should cover us. The CDN endpoint on our side (it’s a pull model) has to support SSL as well so it’s an encrypted handshake on both legs, but that’s minor traffic and easily doable.
With websockets we’ll just try and see when all dependencies are in place. We don’t anticipate any particular problems there, and when it works it should work for more people. Misconfigured or old proxies tend to interfere with HTTP websocket traffic they don’t understand, but those same proxies will just forward on the encrypted HTTPS traffic.
Of course, our load balancers have to support SSL as well, so let’s take a look at how that works in our infrastructure. Whether our SSL setup is typical or not I have no idea, but here’s how we currently do SSL:
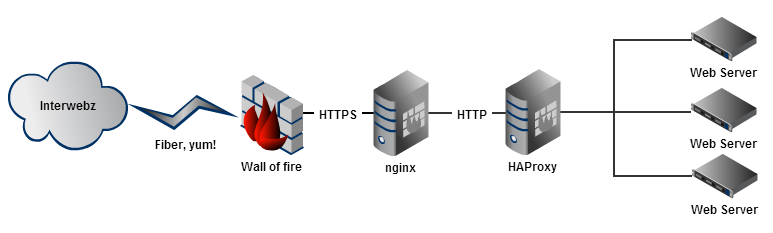
HTTPS traffic goes to nginx on the load balancer machines and terminates there. From there a plain HTTP request is made to HAProxy which delegates the request to whichever web server set it should go to. The response then goes back along the same path. So you have a secure connection all the way to us, but inside our internal network it’s transitioned to a regular HTTP request.
So what’s changing? Logically we’re not changing much, we’re just switching from nginx to HAProxy for the terminator. The request now goes all the way to HAProxy (specifically, a process only for SSL termination) then to the HTTP front-end to continue to a web server. This is both a management-easing change (one install and config via puppet) and hope that HAProxy handles SSL more efficiently, since CPU load on the balancers is an unknown once we go full SSL. An HAProxy instance (without crazy) only ties to a single core, but you can have many SSL processes doing termination all feeding to the single HTTP front-end process. With this approach, the heavy load does scale out across our 12 physical core machines well…we hope. If it doesn’t work then we need active/active load balancers, which is another project we’re working on just in case.
Now here’s the really fun part, certificates. Let’s take a look a sample of domains we’d have to cover:
- stackoverflow.com
- meta.stackoverflow.com
- stackexchange.com
- careers.stackoverflow.com
- gaming.stackexchange.com
- meta.gaming.stackexchange.com
- superuser.com
- meta.superuser.com
Ok so the top level domains are easy, a SAN cert which allows many domains on a single cert – we can sanely combine up to 100 here. So what about all of our *.stackexchange.com domains? A wildcart cert, excellent we’re knocking these out like crazy. What about meta.*.stackexchange.com? Damn. Can’t do that. You can’t have a wildcard of that form - at least not one supported by most major browsers, which means effectively it’s not an option. Let’s see where these restrictions originate.
Section 3.1 of RFC 2818 is very open/ambiguous on wildcard usage, it states:
Names may contain the wildcard character * which is considered to match any single domain name component or component fragment. E.g.,
*.a.commatches foo.a.com but notbar.foo.a.com.f*.commatchesfoo.combut notbar.com.
It doesn’t really disallow meta.*.stackexchange.com or *.*.meta.stackexchange.com. So far so good…then some jerk tried to make a certificate for ***.com** which obviously wasn’t good, so that was revoked and disallowed. So what happened? Some other jerk went and tried ***.*.com**. Well, that ruined it for everyone. Thanks, jerks.
The rules were further clarified in Section 6.4.3 of RFC 6125 which says (emphasis mine):
The client SHOULD NOT attempt to match a presented identifier in which the wildcard character comprises a label other than the left-most label (e.g., do not match
bar.*.example.net)
This means no *.*.stackexchange.com or meta.*.stackexchange.com. Enough major browsers conform to this RFC that it’s a non-option. So what do we do? We thought of a few approaches. We would prefer not to change domains for our content, so the first thought was setting up an automated operation to install new entries on a SAN cert for each new meta created. As we worked though this option, we found several major problems:
- We are limited to approximately 100 entries per SAN cert, so every new 100 metas means another IP allocation on our load balancer. (This appears to be an industry restriction due to abuse, rather than a technical limitation)
- The IP usage issues would be multiplied as we move to active/active load balancers, draining our allocated IP ranges faster and putting an even shorter lifetime on this solution.
- It delays site launches, due to waiting on certificates to be requested, generated, merge, received and installed.
- Every site launch has to have a DNS entry for the meta, this exposes us to additional risk of DNS issues and complicates data center failover.
- We have to build an entire system to support this, rotating through certificates a bit rube goldberg style, installing into HAProxy, writing to BIND, etc.
So what do we do? We’re not 100% decided yet – we’re still researching and talking with people. We may have to do the above. The alternatives would be to shift child meta domains to be on the same level as *.stackexchange.com or under a common *.x.stackexchange.com for which we can get a wildcard. If we shift domains, we have to put in redirects and update URLs in already posted content to point to the new place (to save users a redirect). Also changing the domain to not be a child means setting a child cookie on the parent domain that is shared down is no longer an option – so the login model has to change there but still be as transparent and easy as possible.
Now let’s say we do all of that and it all works, what happens to our google rank when we start sending everyone to HTTPS, including crawlers? We don’t know, and it’s a little scary…so we’ll test the best we can with a slow rollout. Hopefully, it won’t matter. We have to send everything to SSL because otherwise logged-in users would get a redirect every time after clicking an http:// link from google…that needs to be an https:// from the search results.
Some of those simple items above aren’t so simple, especially changing child meta logins and building cert grabbing/installing system. So is that why we aren’t doing it? Of course not, we love pain – so we are actively working on SSL now that some of our third party content providers are ready. We’re not ignoring the request for enhanced security and privacy while using our network, it’s just not as simple as many people seem to think it is at first glance - not when you’re dealing with our domain variety. We’ll be working on it over the next 6-8 weeks.