Running Stack Overflow on SQL 2014 CTP 2
Ok let’s start with the obvious, why run Stack Overflow on pre-release software? If no one tests anything, it only means one thing: more bugs at release. We have the opportunity to test the hell out of the 2014 platform. We can encounter, triage and in most cases, get bugs resolved before release. What company doesn’t want testers for their software in real world environments whenever possible? I would like to think all of them do, just not all have the resources to make it happen.
All of that adds up to it being a huge win for us to test pre-release software in many cases. First there’s the greedy benefit: we can help ourselves to make sure our pain points with the current version are resolved in the next. Then there’s something we love doing even more: helping others. By eliminating bugs from the RTM release and being able to blog about upgrade experiences such as this, we hope it helps others…just as posting a question publicly does.
It’s worth noting this isn’t an isolated case. When we make changes to the open source libraries we release, you can bet they’ve run that code has already run under heavy stackoverflow.com load before we push a library update out - we can’t think of a better test in most cases.
I’m going to elaborate on why we upgraded. If you’'’re curious about the upgrade to SQL 2014 itself definitely check out Brent Ozar’s post: Update on Stack Overflow’s Recovery Strategy with SQL Server 2014.
What’s in SQL 2014 for us?
We have one major issue with SQL 2012 that’s solved by upgrading to SQL 2014: AlwaysOn replica availability in the disconnected state is now read-only instead of offline. Currently (in SQL 2012) when a server loses quorum in a cluster, the AlwaysOn availability groups on that server shut down, and the databases in it become unavailable. In SQL 2014, this doesn’t happen; minority nodes go into read-only mode rather than offline.
That’s it, that’s all the reason we needed for upgrading. That’s if it works as advertised, how do we know unless we test it? Much better to test it now while we can actually get bugs fixed before RTM. The net result in a communication down scenario is that Stack Overflow goes into read-only mode automatically, instead of offline. We want to be online at all times (who doesn’t?), but at worst case being read-only isn’t bad. Being online in read-only mode means all of our users can still find existing answers and the world keeps spinning.
To be fair, we want some of the other goodies in 2014 as well. The improved query optimizer (due to better cardinality estimations) is already showing significant savings for some of our most active queries (for example: the query that fetches comments and runs 200 times per second is 30% cheaper). We can now have 8 read-only replicas per cluster (limited to 4 in 2012).
Problems with SQL 2012 quorum behavior
Let’s start by understanding Windows Server clustering quorum behavior. Quorum isn’t anything fancy, it’s exactly what you think. In Windows clustering it means that a server needs to be able to see the majority of the total cluster to maintain quorum. Without this, it assumes that the minority fraction of servers it can see (possibly just itself) are the minority affected by whatever connectivity issue exists. The amount of servers required for quorum can change and shift as servers go up and down for reboots, etc. This is known as dynamic quorum. Dynamic quorum takes 90 seconds to change the calculation in most of our unplanned disconnect cases, this is important because losing several nodes quickly can result in all your databases being offline everywhere…because everyone lost quorum.
Let’s take a look specifically at Stack Overflow. In our current setup we have 2 SQL clusters that are of the same configuration for the sake of this discussion. In each cluster, we have 2 servers in the New York data center and 1 in the Oregon data center:
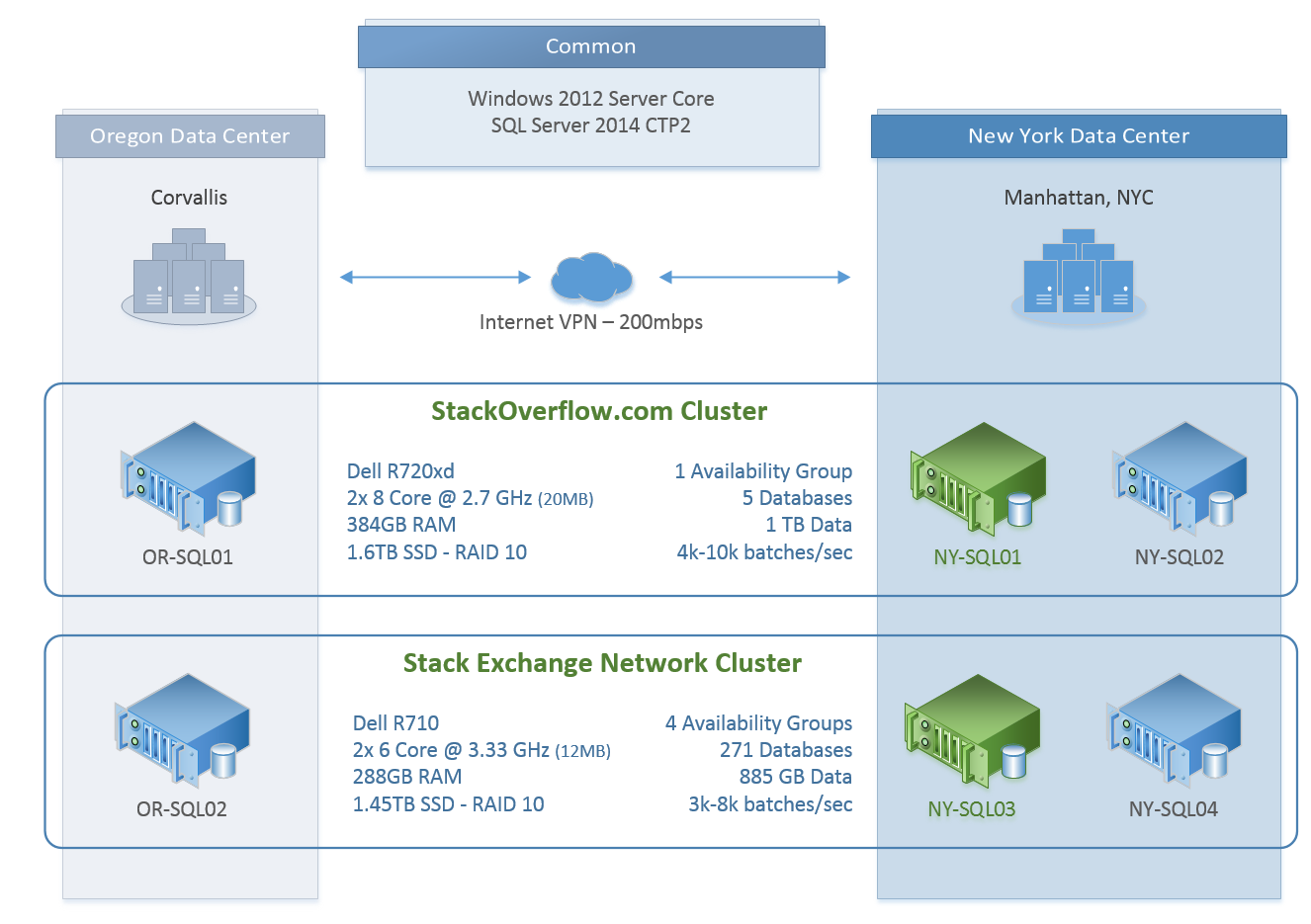
Now the key here is that VPN link from one data center to the other. When the internet blips (as it tends to do), the VPN mesh drops and the Oregon side loses quorum and (in 2012) goes offline. What would be a read-only data center that continued to operate without a connection to New York is essentially dead in the water. Dammit.
Well, that sucks. What’s would be worse than losing a read-only data center? If Oregon blips less than 90 seconds after a node in New York goes down for maintenance and dynamic quorum hasn’t adjusted yet, all nodes go down, and stackoverflow.com with them. That’s what we call a bad day. Yes, we can avoid this by removing Oregon’s node weight before maintenance (and we do just that), but it still leaves Oregon totally offline.
How SQL 2014 makes it all better
It’s important to understand that SQL AlwaysOn availability groups are built on Windows Server clustering. When a cluster node loses quorum, it will send a signal to SQL letting it know. In SQL 2012 the handle of that signal is to shut down the availability group and the databases within it become unavailable. In SQL 2014, the availability groups handle that signal differently, by staying a read-only replica.
The whole point of not being writable when in the minority is the prevent a split brain situation where 2 (or more) separate groups both have a writing node…resulting in a forked database. Being read-only doesn’t cause a split brain, so honestly this is the fail-back-to-read-only behavior we expected SQL 2012 to have.
This simple change lets us do more than just stay online, it opens up new possibilities without re-architecting our primary data store. Let’s say, hypothetically, we have a few servers in Europe: a few web servers, whatever networking hardware, a few support VMs, and a SQL read-only replica. What happens when the VPN to this hypothetical node goes down? It’s still online just with data that’s not getting updated…that’s not a terrible alternative to being offline and traffic having to be routed away immediately. Even if we needed to re-route traffic, we have time to make that decision of for whatever mechanism accomplishing that to kick in.
What if that scenario wasn’t so hypothetical?