What it takes to run Stack Overflow
I like to think of Stack Overflow as running with scale but not at scale. By that I meant we run very efficiently, but I still don’t think of us as “big”, not yet. Let’s throw out some numbers so you can get an idea of what scale we are at currently. Here are some quick numbers from a 24 hour window few days ago - November 12th, 2013 to be exact. These numbers are from a typical weekday and only include our active data center - what we host. Things like hits/bandwidth to our CDN are not included, they don’t hit our network.
- 148,084,883 HTTP requests to our load balancer
- 36,095,312 of those were page loads
- 833,992,982,627 bytes (776 GB) of HTTP traffic sent
- 286,574,644,032 bytes (267 GB) total received
- 1,125,992,557,312 bytes (1,048 GB) total sent
- 334,572,103 SQL Queries (from HTTP requests alone)
- 412,865,051 Redis hits
- 3,603,418 Tag Engine requests
- 558,224,585 ms (155 hours) spent running SQL queries
- 99,346,916 ms (27 hours) spent on redis hits
- 132,384,059 ms (36 hours) spent on Tag Engine requests
- 2,728,177,045 ms (757 hours) spent processing in ASP.Net
(I should do a post on how we get those numbers quickly, and how just having those numbers is worth the effort)
Keep in mind these are for the entire Stack Exchange network but still don’t include everything. With the exception of the 2 totals, these numbers are only from HTTP requests we log to look at performance. Also, whoa that’s a lot of hours in a day, how do you do that? We like to call it magic, other people call it “multiple servers with multi-core processors” - but we’ll stick with magic. Here’s what runs the Stack Exchange network in that data center:
- 4 MS SQL Servers
- 11 IIS Web Servers
- 2 Redis Servers
- 3 Tag Engine servers (anything searching by tag hits this, e.g. /questions/tagged/c++)
- 3 elasticsearch servers
- 2 Load balancers (HAProxy)
- 2 Networks (each a Nexus 5596 + Fabric Extenders)
- 2 Cisco 5525-X ASAs (think Firewall)
- 2 Cisco 3945 Routers
Here’s what that looks like:

We don’t only run the sites, The rest of those servers in the nearest rack are VMs and other infrastructure for auxiliary things not involved in serving the sites directly, like deployments, domain controllers, monitoring, ops database for sysadmin goodies, etc. Of that list above, 2 SQL servers were backups only until very recently - they are now used for read-only loads so we can keep on scaling without thinking about it for even longer (this mainly consists of the Stack Exchange API). Two of those web servers are for dev and meta, running very little traffic.
Core Hardware
When you remove redundancy here’s what Stack Exchange needs to run (while maintaining our current level of performance):
- 2 SQL servers (SO is on one, everything else on another…they could run on a single machine still having headroom though)
- 2 Web Servers (maybe 3, but I have faith in just 2)
- 1 Redis Server
- 1 Tag Engine server
- 1 elasticsearch server
- 1 Load balancer
- 1 Network
- 1 ASA
- 1 Router
(we really should test this one day by turning off equipment and seeing what the breaking point is)
Now there are a few VMs and such in the background to take care of other jobs, domain controllers, etc., but those are extremely lightweight and we’re focusing on Stack Overflow itself and what it takes to render all the pages at full speed. If you want a full apples to apples, throw a single VMware server in for all of those stragglers. So that’s not a large number of machines, but the specs on those machines typically aren’t available in the cloud, not at reasonable prices. Here are some quick “scale up” server notes:
- SQL servers have 384 GB of memory with 1.8TB of SSD storage
- Redis servers have 96 GB of RAM
- elastic search servers 196 GB of RAM
- Tag engine servers have the fastest raw processors we can buy
- Network cores have 10 Gb of bandwidth on each port
- Web servers aren’t that special at 32 GB and 2x quad core and 300 GB of SSD storage.
- Servers that don’t have 2x 10Gb (e.g. SQL) have 4x 1 Gb of network bandwidth
Is 20 Gb massive overkill? You bet your ass it is, the active SQL servers average around 100-200 Mb out of that 20 Gb pipe. However, things like backups, rebuilds, etc. can completely saturate it due to how much memory and SSD storage is present, so it does serve a purpose.
Storage
We currently have about 2 TB of SQL data (1.06 TB / 1.63 TB across 18 SSDs on the first cluster, 889 GB / 1.45 TB across 4 SSDs on the second cluster), so that’s what we’d need on the cloud (hmmm, there’s that word again). Keep in mind that’s all SSD. The average write time on any of our databases is 0 milliseconds, it’s not even at the unit we can measure because the storage handles it that well. With the database in memory and 2 levels of cache in front of it, Stack Overflow actually has a 40:60 read-write ratio. Yeah, you read that right, 60% of our database disk access is writes (you should know your read/write workload too). There’s also storage for each web server - 2x 320GB SSDs in a RAID 1. The elastic boxes need about 300 GB a piece and do perform much better on SSDs (we write/re-index very frequently).
It’s worth noting we do have a SAN, an Equal Logic PS6110X that’s 24x900GB 10K SAS drives on a 2x 10Gb link (active/standby) to our core network. It’s used exclusively for the VM servers as shared storage for high availability but does not really support hosting our websites. To put it another way, if the SAN died the sites would not even notice for a while (only the VM domain controllers are a factor).
Put it all together
Now, what does all that do? We want performance. We need performance. Performance is a feature, a very important feature to us. The main page loaded on all of our sites is the question page, affectionately known as Question/Show (its route name) internally. On November 12th, that page rendered in an average of 28 milliseconds. While we strive to maintain 50ms, we really try and shave every possible millisecond off your pageload experience. All of our developers are certifiably anal curmudgeons when it comes to performance, so that helps keep times low as well. Here are the other top hit pages on SO, average render time on the same 24 hour period as above:
- Question/Show: 28 ms (29.7 million hits)
- User Profiles: 39 ms (1.7 million hits)
- Question List: 78 ms (1.1 million hits)
- Home page: 65 ms (1 million hits) (that’s very slow for us - Kevin Montrose will be fixing this perf soon: here’s the main cause)
We have high visibility of what goes into our page loads by recording timings for every single request to our network. You need some sort of metrics like this, otherwise what are you basing your decisions on? With those metrics handy, we can make easy to access, easy to read views like this:

After that the percentage of hits drops off dramatically, but if you’re curious about a specific page I’m happy to post those numbers too. I’m focusing on render time here because that’s how long it takes our server to produce a webpage, the speed of transmission is an entirely different (though admittedly, very related) topic I’ll cover in the future.
Room to grow
It’s definitely worth noting that these servers run at very low utilization. Those web servers average between 5-15% CPU, 15.5 GB of RAM used and 20-40 Mb/s network traffic. The SQL servers average around 5-10% CPU, 365 GB of RAM used, and 100-200 Mb/s of network traffic. This affords us a few major things: general room to grow before we upgrade, headroom to stay online for when things go crazy (bad query, bad code, attacks, whatever it may be), and the ability to clock back on power if needed. Here’s a view from Opserver of our web tier taken just now:
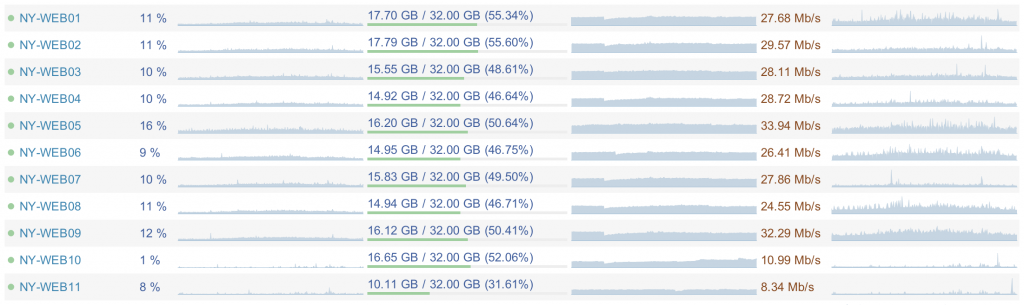
The primary reason the utilization is so low is efficient code. That’s not the topic of this post, but efficient code is critical to stretching your hardware further. Anything you’re doing that doesn’t need doing costs more than not doing it, that continues to apply if it’s a subset of your code that could be more efficient. That cost comes in the form of: power consumption, hardware cost (since you need more/bigger servers), developers understanding something more complicated (to be fair, this can go both ways, efficient isn’t necessarily simple) and likely a slower page render - meaning less users sticking around for another page load…or being less likely to come back. The cost of inefficient code can be higher than you think.
Now that we know how Stack Overflow performs on its current hardware, next time we can see why we don’t run in the cloud.