HTTPS on Stack Overflow: The End of a Long Road
Today, we deployed HTTPS by default on Stack Overflow.
All traffic is now redirected to https:// and Google links will change over the next few weeks.
The activation of this is quite literally flipping a switch (feature flag), but getting to that point has taken years of work.
As of now, HTTPS is the default on all Q&A websites.
We’ve been rolling it out across the Stack Exchange network for the past 2 months. Stack Overflow is the last site, and by far the largest. This is a huge milestone for us, but by no means the end. There’s still more work to do, which we’ll get to. But the end is finally in sight, hooray!
Fair warning: This is the story of a long journey. Very long. As indicated by your scroll bar being very tiny right now. While Stack Exchange/Overflow is not unique in the problems we faced along the way, the combination of problems is fairly rare. I hope you find some details of our trials, tribulations, mistakes, victories, and even some open source projects that resulted along the way to be helpful. It’s hard to structure such an intricate dependency chain into a chronological post, so I’ll break this up by topic: infrastructure, application code, mistakes, etc.
I think it’s first helpful to preface with a list of problems that makes our situation somewhat unique:
- We have hundreds of domains (many sites and other services)
- Many second-level domains (stackoverflow.com, stackexchange.com, askubuntu.com, etc.)
- Many 4th level domains (e.g. meta.gaming.stackexchange.com)
- We allow user submitted & embedded content (e.g. images and YouTube videos in posts)
- We serve from a single data center (latency to a single origin)
- We have ads (and ad networks)
- We use websockets, north of 500,000 active at any given (connection counts)
- We get DDoSed (proxy)
- We have many sites & apps communicating via HTTP APIs (proxy issues)
- We’re obsessed with performance (maybe a little too much)
Since this post is a bit crazy, links for your convenience:
- The Beginning
- Quick Specs
- Infrastructure
- Applications/Code
- Unknowns
- Mistakes
- Open Source
- Next Steps
The Beginning
We began thinking about deploying HTTPS on Stack Overflow back in 2013. So the obvious question: It’s 2017. What the hell took 4 years? The same 2 reasons that delay almost any IT project: dependencies and priorities. Let’s be honest, the information on Stack Overflow isn’t as valuable (to secure) as most other data. We’re not a bank, we’re not a hospital, we don’t handle credit card payments, and we even publish most of our database both by HTTP and via torrent once a quarter. That means from a security standpoint, it’s just not as high of a priority as it is in other situations. We also had far more dependencies than most, a rather unique combination of some huge problem areas when deploying HTTPS. As you’ll see later, some of the domain problems are also permanent.
The biggest areas that caused us problems were:
- User content (users can upload images or specify URLs)
- Ad networks (contracts and support)
- Hosting from a single data center (latency)
- Hundreds of domains, at multiple levels (certificates)
Okay, so why do we want HTTPS on our websites? Well, the data isn’t the only thing that needs security. We have moderators, developers, and employees with various levels of access via the web. We want to secure their communications with the site. We want to secure every user’s browsing history. Some people live in fear every day knowing that someone may find out they secretly like monads. Google also gives a boost to HTTPS websites in ranking (though we have no clue how much).
Oh, and performance. We love performance. I love performance. You love performance. My dog loves performance. Let’s have a performance hug. That was nice. Thank you. You smell nice.
Quick Specs
Some people just want the specs, so quick Q&A here (we love Q&A!):
- Q: Which protocols do you support?
- A: TLS 1.0, 1.1, 1.2 (Note: Fastly has a TLS 1.0 and 1.1 deprecation plan). TLS 1.3 support is coming
- Q: Do you support SSL v2, v3?
- A: No, these are broken, insecure protocols. Everyone should disable them ASAP.
- Q: Which ciphers do you support?
- A: At the CDN, we use Fastly’s default suite
- A: At our load balancer, we use Mozilla’s Modern compatibility suite
- Q: Does Fastly connect to the origin over HTTPS?
- A: Yes, if the CDN request is HTTPS, the origin request is HTTPS.
- Q: Do you support forward secrecy?
- A: Yes
- Q: Do you support HSTS?
- A: Yes, we’re ramping it up across Q&A sites now. Once done we’ll move it to the edge.
- Q: Do you support HPKP?
- A: No, and we likely won’t.
- Q: Do you support SNI?
- A: No, we have a combined wildcard certificate for HTTP/2 performance reasons (details below).
- Q: Where do you get certificates?
- A: We use DigiCert, they’ve been awesome.
- Q: Do you support IE 6?
- A: This move finally kills it, completely. IE 6 does not support TLS (default - though 1.0 can be enabled), we do not support SSL. With 301 redirects in place, most IE6 users can no longer access Stack Overflow. When TLS 1.0 is removed, none can.
- Q: What load balancer do you use?
- Q: What’s the motivation for HTTPS?
- A: People kept attacking our admin routes like stackoverflow.com/admin.php.
Certificates
Let’s talk about certificates, because there’s a lot of misinformation out there. I’ve lost count of the number of people who say you just install a certificate and you’re ready to go on HTTPS. Take another look at the tiny size of your scroll bar and take a wild guess if I agree. We prefer the SWAG method for our guessing.
The most common question we get: “Why not use Let’s Encrypt?”
Answer: because they don’t work for us. Let’s Encrypt is doing a great thing. I hope they keep at it. If you’re on a single domain or only a few domains, they’re a pretty good option for a wide variety of scenarios. We are simply not in that position. Stack Exchange has hundreds of domains. Let’s Encrypt doesn’t offer wildcards. These two things are at odds with each other. We’d have to get a certificate (or two) every time we deployed a new Q&A site (or any other service). That greatly complicates deployment, and either a) drops non-SNI clients (around 2% of traffic these days) or b) requires far more IP space than we have.
Another reason we want to control the certificate is we need to install the exact same certificates on both our local load balancers and our CDN/proxy provider. Unless we can do that, we can’t failover (away from a proxy) cleanly in all cases. Anyone that has the certificate pinned via HPKP (HTTP Public Key Pinning) would fail validation. We’re evaluating whether we’ll deploy HPKP, but we’ve prepped as if we will later.
I’ve gotten a lot of raised eyebrows at our main certificate having all of our primary domains + wildcards. Here’s what that looks like:
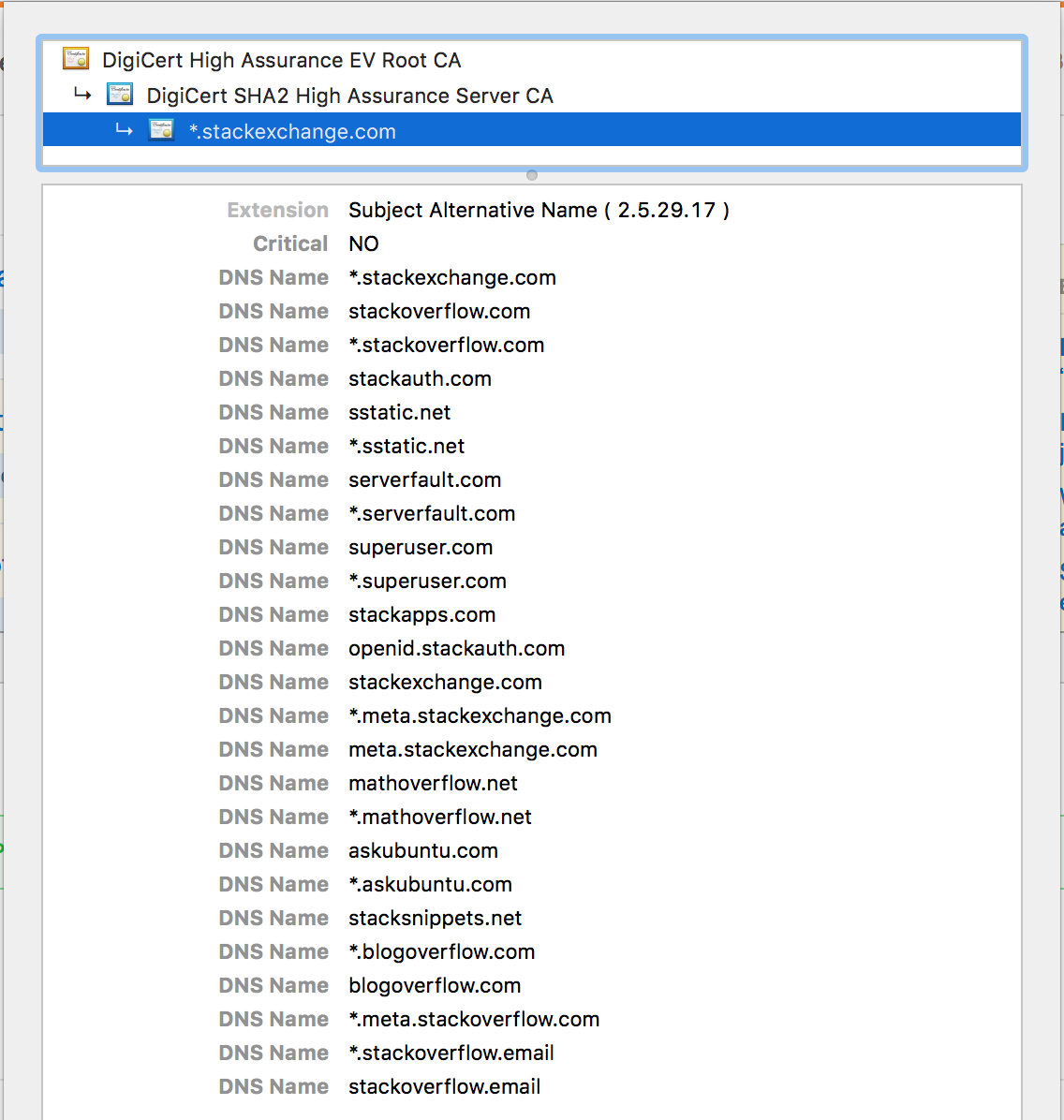
Why do this? Well, to be fair, DigiCert is the one who does this for us upon request. Why go through the pain of a manual certificate merge for every change? First, because we wanted to support as many people as possible. That includes clients that don’t support SNI (for example, Android 2.3 was a big thing when we started). But also because of HTTP/2 and reality. We’ll cover that in a minute.
Certificates: Child Metas (meta.*.stackexchange.com)
One of the tenets of the Stack Exchange network is having a place to talk about each Q&A site.
We call it the “second place”.
As an example, meta.gaming.stackexchange.com exists to talk about gaming.stackexchange.com.
So why does that matter? Well, it doesn’t really. We only care about the domain here. It’s 4 levels deep.
I’ve covered this before, but where did we end up?
First the problem: *.stackexchange.com does cover gaming.stackexchange.com (and hundreds of other sites), but it does not cover meta.gaming.stackexchange.com.
RFC 6125 (Section 6.4.3) states that:
The client SHOULD NOT attempt to match a presented identifier in which the wildcard character comprises a label other than the left-most label (e.g., do not match
bar.*.example.net)
That means we cannot have a wildcard of meta.*.stackexchange.com. Well, shit.
So what do we do?
- Option 1: Deploying SAN certificates
- We’d need 3 (the limit is ~100 domains per), we’d need to dedicate 3 IPs, and we’d complicate new site launches (until the scheme changed, which it already has)
- We’d have to pay for 3 custom certs for all time at the CDN/proxy
- We’d have to have a DNS entry for every child meta under the
meta.*scheme- Due to the rules of DNS, we’d actually have to add a DNS entry for every single site, complicating site launches and maintenance.
- Option 2: Move all domains to
*.meta.stackexchange.com?- We’d have a painful move, but it’s 1-time and simplifies all maintenance and certificates
- We’d have to build a global login system (details here)
- This solution also creates a
includeSubDomainsHSTS preloading problem (details here)
- Option 3: We’ve had a good run, shut ‘er down
- This one is the easiest, but was not approved
We built a global login system and later moved the child meta domains (with 301s), and they’re now at their new homes. For example, https://gaming.meta.stackexchange.com.
After doing this, we realized how much of a problem the HSTS preload list was going to be simply because those domains ever existed.
I’ll cover that near the end, as it’s still in progress.
Note that the problems here are mirrored on our journey for things like meta.pt.stackoverflow.com, but were more limited in scale since only 4 non-English versions of Stack Overflow exist.
Oh, and this created another problem in itself.
By moving cookies to the top-level domain and relying on the subdomain inheritance of them, we now had to move domains.
As an example, we use SendGrid to send email in our new system (rolling out now).
The reason that it sends from stackoverflow.email with links pointed at sg-links.stackoverflow.email (a CNAME pointed to them), is so that your browser doesn’t send any sensitive cookies.
If it was sg-links.stackoverflow.com (or anything beneath stackoverflow.com), your browser would send our cookies to them.
This is a concrete example of new things, but there were also miscellaneous not-hosted-by-us services under our DNS.
Each one of these subdomains had to be moved or retired to get out from under our authenticated domains…or else we’d be sending your cookies to not-our-servers.
It’d be a shame to do all this work just to be leaking cookies to other servers at the end of it.
We tried to work around this in one instance by proxying one of our Hubspot properties for a while, stripping the cookies on the way through. But unfortunately, Hubspot uses Akamai which started treating our HAProxy instance as a bot and blocking it in oh so fun various ways on a weekly basis. It was fun, the first 3 times. So anyway, that really didn’t work out. It went so badly we’ll never do it again.
Were you curious why we have the Stack Overflow Blog at https://stackoverflow.blog/? Yep, security. It’s hosted on an external service so that the marketing team and others can iterate faster. To facilitate this, we needed it off the cookied domains.
The above issues with meta subdomains also introduced related problems with HSTS, preloading, and the includeSubDomains directive.
But we’ll see why that’s become a moot point later.
Performance: HTTP/2
The conventional wisdom long ago was that HTTPS was slower. And it was. But times change. We’re not talking about HTTPS anymore. We’re talking about HTTPS with HTTP/2. While HTTP/2 doesn’t require encryption, effectively it does. This is because the major browsers require a secure connection to enable most of its features. You can argue specs and rules all day long, but browsers are the reality we all live in. I wish they would have just called it HTTPS/2 and saved everyone a lot of time. Dear browser makers, it’s not too late. Please, listen to reason, you’re our only hope!
HTTP/2 has a lot of performance benefits, especially with pushing resources opportunistically to the user ahead of asking for them. I won’t write in detail about those benefits, Ilya Grigorik has done a fantastic job of that already. As a quick overview, the largest optimizations (for us) include:
- Request/Response Multiplexing
- Server Push
- Header Compression
- Stream Prioritization
- Fewer Origin Connections
Hey wait a minute, what about that silly certificate?
A lesser-known feature of HTTP/2 is that you can push content not on the same domain, as long as certain criteria are met:
- The origins resolve to the same server IP address.
- The origins are covered by the same TLS certificate (bingo!)
So, let’s take a peek at our current DNS:
λ dig stackoverflow.com +noall +answer
; <<>> DiG 9.10.2-P3 <<>> stackoverflow.com +noall +answer
;; global options: +cmd
stackoverflow.com. 201 IN A 151.101.1.69
stackoverflow.com. 201 IN A 151.101.65.69
stackoverflow.com. 201 IN A 151.101.129.69
stackoverflow.com. 201 IN A 151.101.193.69
λ dig cdn.sstatic.net +noall +answer
; <<>> DiG 9.10.2-P3 <<>> cdn.sstatic.net +noall +answer
;; global options: +cmd
cdn.sstatic.net. 724 IN A 151.101.193.69
cdn.sstatic.net. 724 IN A 151.101.1.69
cdn.sstatic.net. 724 IN A 151.101.65.69
cdn.sstatic.net. 724 IN A 151.101.129.69
Heyyyyyy, those IPs match, and they have the same certificate!
This means that we can get all the wins of HTTP/2 server pushes without harming HTTP/1.1 users.
HTTP/2 gets push and HTTP/1.1 gets domain sharding (via sstatic.net).
We haven’t deployed server push quite yet, but all of this is in preparation.
So in regards to performance, HTTPS is only a means to an end. And I’m okay with that. I’m okay saying that our primary drive is performance, and security for the site is not. We want security, but security alone in our situation is not enough justification for the time investment needed to deploy HTTPS across our network. When you combine all the factors above though, we can justify the immense amount of time and effort required to get this done. In 2013, HTTP/2 wasn’t a big thing, but that changed as support increased and ultimately helped as a driver for us to invest time in HTTPS.
It’s also worth noting that the HTTP/2 landscape changed quite a bit during our deployment. The web moved from SPDY to HTTP/2 and NPN to ALPN. I won’t cover all that because we didn’t do anything there. We watched, and benefited, but the giants of the web were driving all of that. If you’re curious though, Cloudflare has a good write up of these moves.
HAProxy: Serving up HTTPS
We deployed initial HTTPS support in HAProxy back in 2013. Why HAProxy? Because we’re already using it and they added support back in 2013 (released as GA in 2014) with version 1.5. We had, for a time, nginx in front of HAProxy (as you can see in the last blog post). But simpler is often better, and eliminating a lot of conntrack, deployment, and general complexity issues is usually a good idea.
I won’t cover a lot of detail here because there’s simply not much to cover. HAProxy supports HTTPS natively via OpenSSL since 1.5 and the configuration is straightforward. Our configuration highlights are:
- Run on 4 processes
- 1 is dedicated to HTTP/front-end handling
- 2-4 are dedicated to HTTPS negotiation
- HTTPS front-ends are connected to HTTP backends via an abstract named socket. This reduces overhead tremendously.
- Each front-end or “tier” (we have 4: Primary, Secondary, Websockets, and dev) has corresponding :443 listeners.
- We append request headers (and strip ones you’d send - nice try) when forwarding to the web tier to indicate how a connection came in.
- We use the Modern compatibility cipher suite recommended by Mozilla. Note: this is not the same suite our CDN runs.
HAProxy was the relatively simple and first step of supporting a :443 endpoint with valid SSL certificates. In retrospect, it was only a tiny spec of the effort needed.
Here’s a logical layout of what I described above…and we’ll cover that little cloud in front next:

CDN/Proxy: Countering Latency with Cloudflare & Fastly
One of the things I’m most proud of at Stack Overflow is the efficiency of our stack. That’s awesome, right? Running a major website on a small set of servers from one data center? Nope. Not so much. Not this time. While it’s awesome to be efficient for some things, when it comes to latency it suddenly becomes a problem. We’ve never needed a lot of servers. We’ve never needed to expand to multiple locations (but yes, we have another for DR). This time, that’s a problem. We can’t (yet!) solve fundamental problems with latency, due to the speed of light. We’re told someone else is working on this, but there was a minor setback with tears in the fabric of space-time and losing the gerbils.
When it comes to latency, let’s look at the numbers. It’s almost exactly 40,000km around the equator (worst case for speed of light round-trip). The speed of light is 299,792,458 meters/second in a vacuum. Unfortunately, a lot of people use this number, but most fiber isn’t in a vacuum. Realistically, most optical fiber is 30-31% slower. So we’re looking at (40,075,000 m) / (299,792,458 m/s * .70) = 0.191 seconds, or 191ms for a round-trip in the worst case, right? Well…no, not really. That’s also assuming an optimal path, but going between two destinations on the internet is very rarely a straight line. There are routers, switches, buffers, processor queues, and all sorts of additional little delays in the way. They add up to measurable latency. Let’s not even talk about Mars, yet.
So why does that matter to Stack Overflow? This is an area where the cloud wins. It’s very likely that the server you’re hitting with a cloud provider is relatively local. With us, it’s not. With a direct connection, the further you get away from our New York or Denver data centers (whichever one is active), the slower your experience gets. When it comes to HTTPS, there’s an additional round trip to negotiate the connection before any data is sent. That’s under the best of circumstances (though that’s improving with TLS 1.3 and 0-RTT). And Ilya Grigorik has a great summary here.
Enter Cloudflare and Fastly. HTTPS wasn’t a project deployed in a silo; as you read on, you’ll see that several other projects multiplex in along the way. In the case of a local-to-the-user HTTPS termination endpoint (to minimize that round trip duration), we were looking for a few main criteria:
- Local HTTPS termination
- DDoS protection
- CDN functionality
- Performance equivalent or better than direct-to-us
Preparing for a Proxy: Client Timings
Before moving to any proxy, testing for performance had to be in place.
To do this, we set up a full pipeline of timings to get performance metrics from browsers.
For years now, browsers have included performance timings accessible via JavaScript, via window.performance.
Go ahead, open up the inspector and try it!
We want to be very transparent about this, that’s why details have been available on teststackoverflow.com since day 1.
There’s no sensitive data transferred, only the URIs of resources directly loaded by the page and their timings.
For each page load recorded, we get timings that look like this:
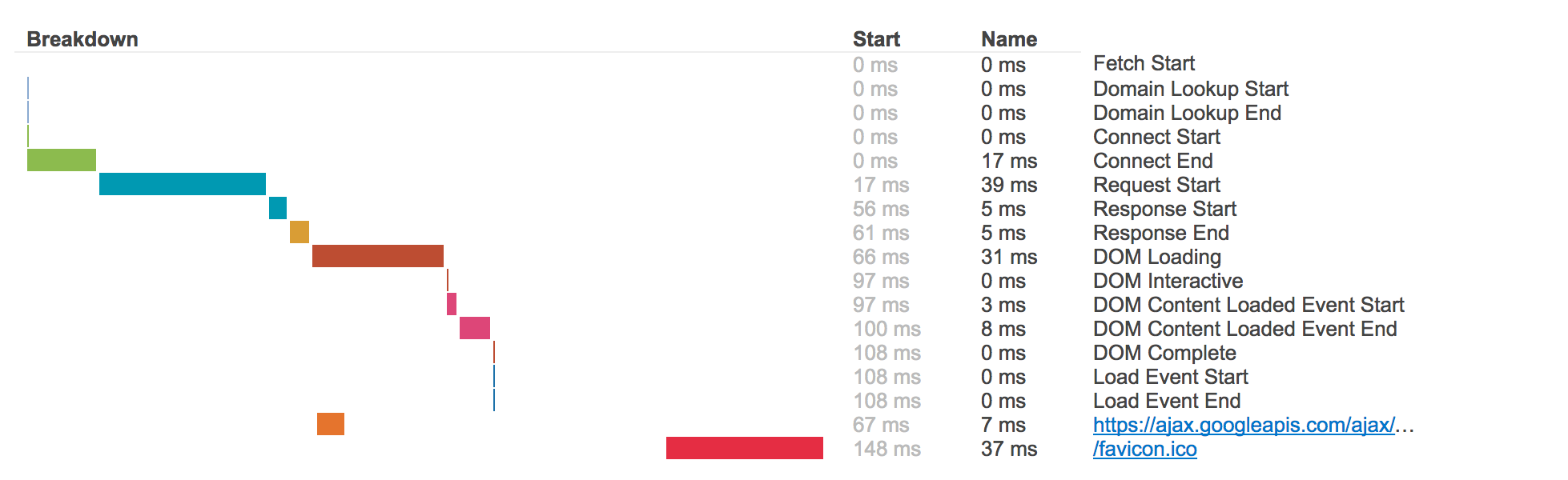
Currently we attempt to record performance timings from 5% of traffic. The process isn’t that complicated, but all the pieces had to be built:
- Transform the timings into JSON
- Upload the timings after a page load completes
- Relay those timings to our backend Traffic Processing Service (it has reports)
- Store those timings in a clustered columnstore in SQL Server
- Relay aggregates of the timings to Bosun (via BosunReporter.NET)
The end result is we now have a great real-time overview of actual user performance all over the world that we can readily view, alert on, and use for evaluating any changes. Here’s a view of timings coming in live:
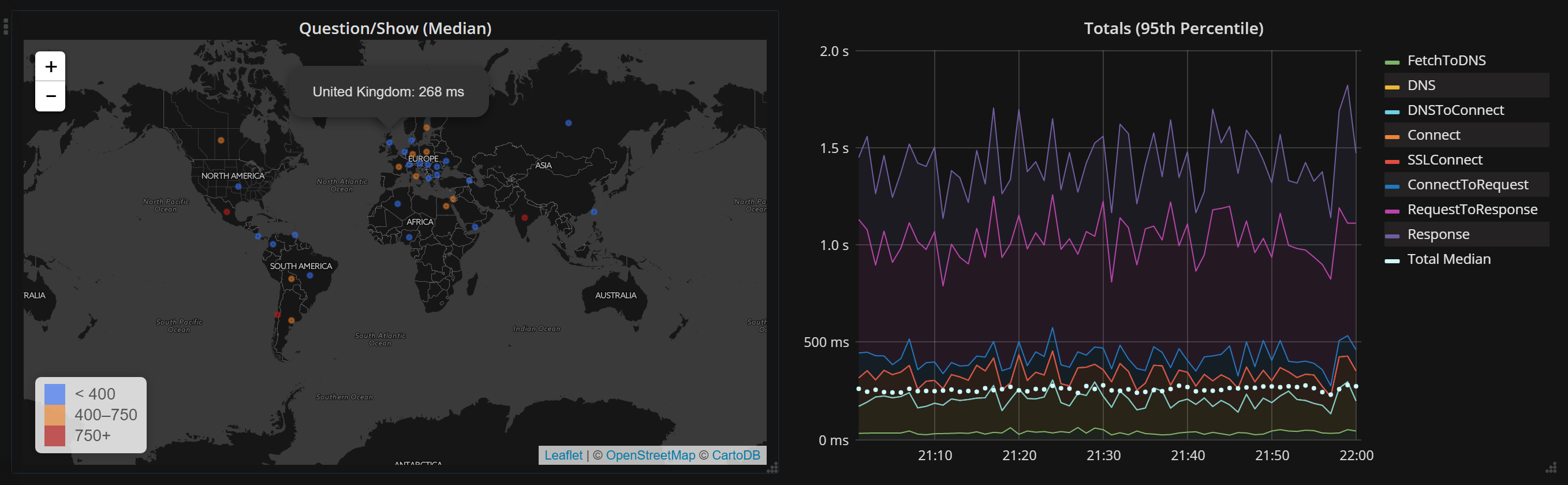
Luckily, we have enough sustained traffic to get useful data here. At this point, we have over 5 billion points (and growing) of data to help drive decisions. Here’s a quick overview of that data:

Okay, so now we have our baseline data. Time to test candidates for our CDN/Proxy setup.
Cloudflare
We evaluated many CDN/DDoS proxy providers. We picked Cloudflare based on their infrastructure, responsiveness, and the promise of Railgun. So how can we do test what life would be like behind Cloudflare all over the world? How many servers would we need to set up to get enough data points? None!
Stack Overflow has an excellent resource here: billions of hits a month.
Remember those client timings we just talked about?
We already have tens of millions of users hitting us every day, so why don’t we ask them?
We can do just that, by embedding an <iframe> in Stack Overflow pages.
Cloudflare was already our cdn.sstatic.net host (our shared, cookieless static content domain) from earlier.
But, this was done with a CNAME DNS record, we served the DNS which pointed at their DNS.
To use Cloudflare as a proxy though, we needed them to serve our DNS.
So first, we needed to test performance of their DNS.
Practically speaking, to test performance we needed to delegate a second-level domain to them, not something.stackoverflow.com, which would have different glue records and sometimes isn’t handled the same way (causing 2 lookups).
To clarify, Top-Level Domains (TLDs) are things like .com, .net, .org, .dance, .duck, .fail, .gripe, .here, .horse, .ing, .kim, .lol, .ninja, .pink, .red, .vodka. and .wtf.
Nope, I’m not kidding (and here’s the full list).
Second-Level Domains (SLDs) are one level below, what most sites would be: stackoverflow.com, superuser.com, etc.
That’s what we need to test the behavior and performance of.
Thus, teststackoverflow.com was born.
With this new domain, we could test DNS performance all over the world.
By embedding the <iframe> for a certain percentage of visitors (we turned it on and off for each test), we could easily get data from each DNS and hosting configuration.
Note that it’s important to test for ~24hours at a minimum here. The behavior of the internet changes throughout the day as people are awake or asleep or streaming Netflix all over the world as it rolls through time zones. So to measure a single country, you really want a full day. Within weekdays, preferably (e.g. not half into a Saturday). Also be aware that shit happens. It happens all the time. The performance of the internet is not a stable thing, we’ve got the data to prove it.
Our initial assumptions going into this was we’d lose some page load performance going through Cloudflare (an extra hop almost always adds latency), but we’d make it up with the increases in DNS performance. The DNS side of this paid off. Cloudflare had DNS servers far more local to the users than we do in a single data center. The performance there was far better. I hope that we can find the time to release this data soon. It’s just a lot to process (and host), and time isn’t something I have in ample supply right now.
Then we began testing page load performance by proxying teststackoverflow.com through Cloudflare, again in the <iframe>.
We saw the US and Canada slightly slower (due to the extra hop), but the rest of the world on par or better.
This lined up with expectations overall, and we proceeded with a move behind Cloudflare’s network.
A few DDoS attacks along the way sped up this migration a bit, but that’s another story.
Why did we accept slightly slower performance in the US and Canada?
Well at ~200-300ms page loads for most pages, that’s still pretty damn fast.
But we don’t like to lose.
We thought Railgun would help us win that performance back.
Once all the testing panned out, we needed to put the pieces in for DDoS protection. This involved installing additional, dedicated ISPs in our data center for the CDN/Proxy to connect to. After all, DDoS protection via a proxy isn’t very effective if you can just go around it. This meant we were serving off of 4 ISPs per data center now, with 2 sets of routers, all running BGP with full tables. It also meant 2 new load balancers, dedicated to CDN/Proxy traffic.
Cloudflare: Railgun
At the time, this setup also meant 2 more boxes just for Railgun. The way Railgun works is by caching the last result of that URL in memcached locally and on Cloudflare’s end. When Railgun is enabled, every page (under a size threshold) is cached on the way out. On the next request, if the entry was in Cloudflare’s edge cache and our cache (keyed by URL), we still ask the web server for it. But instead of sending the whole page back to Cloudflare, it only sends a diff. That diff is applied to their cache and served back to the client. By nature of the pipe, it also meant the gzip compression for transmission moved from 9 web servers for Stack Overflow to the 1 active Railgun box…so this had to be a pretty CPU-beefy machine. I point this out because all of this had to be evaluated, purchased and deployed on our way.
As an example, think about 2 users viewing a question. Take a picture of each browser. They’re almost the same page, so that’s a very small diff. It’s a huge optimization if we can send only that diff down most of the journey to the user.
Overall, the goal here is to reduce the amount of data sent back in hopes of a performance win. And when it worked, that was indeed the case. Railgun also had another huge advantage: requests weren’t fresh connections. Another consequence of latency is the duration and speed of the ramp up of TCP slow start, part of the congestion control that keeps the Internet flowing. Railgun maintains a constant connection to Cloudflare edges and multiplexes user requests, all of them over a pre-primed connection not heavily delayed by slow start. The smaller diffs also lessened the need for ramp up overall.
Unfortunately, we never got Railgun to work without issues in the long run. To my knowledge, we were (at the time) the largest deployment of the technology and we stressed it further than it has been pushed before. Though we tried to troubleshoot it for over a year, we ultimately gave up and moved on. It simply wasn’t saving us more than it was costing us in the end. It’s been several years now, though. If you’re evaluating Railgun, you should evaluate the current version, with the improvements they’ve made, and decide for yourself.
Fastly
Moving to Fastly was relatively recent, but since we’re on the CDN/Proxy topic I’ll cover it now. The move itself wasn’t terribly interesting because most of the pieces needed for any proxy were done in the Cloudflare era above. But of course everyone will ask: why did we move? While Cloudflare was very appealing in many regards - mainly, many data centers, stable bandwidth pricing, and included DNS - it wasn’t the best fit for us anymore. We needed a few things that Fastly simply did to fit us better: more flexibility at the edge, faster change propagation, and the ability to fully automate configuration pushes. That’s not to say Cloudflare is bad, it was just no longer the best fit for Stack Overflow.
Since actions speak louder: If I didn’t think highly of Cloudflare, my personal blog wouldn’t be behind them right now. Hi there! You’re reading it.
The main feature of Fastly that was so compelling to us was Varnish and the VCL. This makes the edge highly configurable. So features that Cloudflare couldn’t readily implement (as they might affect all customers), we could do ourselves. This is simply a different architectural approach to how these two companies work, and the highly-configurable-in-code approach suits us very well. We also liked how open they were with details of infrastructure at conferences, in chats, etc.
Here’s an example of where VCL comes in very handy. Recently we deployed .NET 4.6.2 which had a very nasty bug that set max-age on cache responses to over 2000 years. The quickest way to mitigate this for all of our services affected was to override that cache header as-needed at the edge. As I write this, the following VCL is active:
sub vcl_fetch {
if (beresp.http.Cache-Control) {
if (req.url.path ~ "^/users/flair/") {
set beresp.http.Cache-Control = "public, max-age=180";
} else {
set beresp.http.Cache-Control = "private";
}
}
This allows us to cache user flair for 3 minutes (since it’s a decent volume of bytes), and bypass everything else. This is an easy-to-deploy global solution to workaround an urgent cache poisoning problem across all applications. We’re very, very happy with all the things we’re able to do at the edge now. Luckily we have Jason Harvey who picked up the VCL bits and wrote automated-pushed of our configs. We had to improve on existing libraries in Go here, so check out fastlyctl, another open source bit to come out of this.
Another important facet of Fastly (that Cloudflare also had, but we never utilized due to cost) is using your own certificate. As we covered earlier, we’re already using this in preparation for HTTP/2 pushes. But, Fastly doesn’t do something Cloudflare does: DNS. So we need to solve that now. Isn’t this dependency chain fun?
Global DNS
When moving from Cloudflare to Fastly, we had to evaluate and deploy new (to us) global DNS providers. That in itself in an entirely different post, one that’s been written by Mark Henderson. Along the way, we were also controlling:
- Our own DNS servers (still up as a fall back)
- Name.com servers (for redirects not needing HTTPS)
- Cloudflare DNS
- Route 53 DNS
- Google DNS
- Azure DNS
- …and several others (for testing)
This was a whole project in itself. We had to come up with means to do this efficiently, and so DNSControl was born. This is now an open source project, available on GitHub, written in Go. In short: we push a change in the JavaScript config to git, and it’s deployed worldwide in under a minute. Here’s a sample config from one of our simpler-in-DNS sites, askubuntu.com:
D('askubuntu.com', REG_NAMECOM,
DnsProvider(R53,2),
DnsProvider(GOOGLECLOUD,2),
SPF,
TXT('@', 'google-site-verification=PgJFv7ljJQmUa7wupnJgoim3Lx22fbQzyhES7-Q9cv8'), // webmasters
A('@', ADDRESS24, FASTLY_ON),
CNAME('www', '@'),
CNAME('chat', 'chat.stackexchange.com.'),
A('meta', ADDRESS24, FASTLY_ON),
END)
Okay great, how do you test that all of this is working? Client Timings! The ones we covered above let us test all of this DNS deployment with real-world data, not simulations. But we also need to test that everything just works.
Testing
Client Timings in deploying the above was very helpful for testing performance.
But it wasn’t good for testing configuration.
After all, Client Timings is awesome for seeing the result, but most configuration missteps result in no page load, and therefore no timings at all.
So we had to build httpUnit (yes, the team figured out the naming conflict later…).
This is now another open source project written in Go.
An example config for teststackoverflow.com:
[[plan]]
label = "teststackoverflow_com"
url = "http://teststackoverflow.com"
ips = ["28i"]
text = "<title>Test Stack Overflow Domain</title>"
tags = ["so"]
[[plan]]
label = "tls_teststackoverflow_com"
url = "https://teststackoverflow.com"
ips = ["28"]
text = "<title>Test Stack Overflow Domain</title>"
tags = ["so"]
It was important to test as we changed firewalls, certificates, bindings, redirects, etc. along the way. We needed to make sure every change was good before we activated it for users (by deploying it on our secondary load balancers first). httpUnit is what allowed us to do that and run an integration test suite to ensure we had no regressions.
There’s another tool we developed internally (by our lovely Tom Limoncelli) for more easily managing Virtual IP Address groups on our load balancers.
We test on the inactive load balancer via a secondary range, then move all traffic over, leaving the previous master in a known-good state.
If anything goes wrong, we flip back.
If everything goes right (yay!), we apply changes to that load balancer as well.
This tool is called keepctl (short for keepalived control) - look for this to be open sourced as soon as time allows.
Preparing the Applications
Almost all of the above has been just the infrastructure work. This is generally done by a team of several other Site Reliability Engineers at Stack Overflow and I getting things situated. There’s also so much more that needed doing inside the applications themselves. It’s a long list. I’d grab some coffee and a Snickers.
One important thing to note here is that the architecture of Stack Overflow & Stack Exchange Q&A sites is multi-tenant.
This means that if you hit stackoverflow.com or superuser.com or bicycles.stackexchange.com, you’re hitting the exact same thing.
You’re hitting the exact same w3wp.exe process on the exact same server.
Based on the Host header the browser sends, we change the context of the request.
Several pieces of what follows will be clearer if you understand Current.Site in our code is the site of the request.
Things like Current.Site.Url() and Current.Site.Paths.FaviconUrl are all driven off this core concept.
Another way to make this concept/setup clearer: we can run the entire Q&A network off of a single process on a single server and you wouldn’t know it. We run a single process today on each of 9 servers purely for rolling builds and redundancy.
Global Login
Quite a few of these projects seemed like good ideas on their own (and they were), but were part of a bigger HTTPS picture. Login was one of those projects. I’m covering it first, because it was rolled out much earlier than the other changes below.
For the first 5-6 years Stack Overflow (and Stack Exchange) existed, you logged into a particular site.
As an example, each of stackoverflow.com, stackexchange.com, and gaming.stackexchange.com had their own per-site cookies.
Of note here: meta.gaming.stackexchange.com’s login depended on the cookie from gaming.stackexchange.com flowing to the subdomain.
These are the “meta” sites we talked about with certificates earlier.
Their logins were tied together, you always logged in through the parent.
This didn’t really matter much technically, but from a user experience standpoint it sucked. You had to login to each site.
We “fixed” that with “global auth”, which was an <iframe> in the page that logged everyone in through stackauth.com if they were logged in elsewhere.
Or it tried to.
The experience was decent, but a popup bar telling you to click to reload and be logged in wasn’t really awesome.
We could do better.
Oh and ask Kevin Montrose about mobile Safari private mode. I dare you.
Enter “Universal Login”. Why the name “Universal”? Because global was taken. We’re simple people.
Luckily, cookies are also pretty simple.
A cookie present on a parent domain (e.g. stackexchange.com) will be sent by your browser to all subdomains (e.g. gaming.stackexchange.com).
When you zoom out from our network, we have only a handful of second-level domains:
- askubuntu.com
- mathoverflow.net
- serverfault.com
- stackapps.com
- stackexchange.com
- stackoverflow.com
- superuser.com
Yes, we have other domains that redirect to these, like askdifferent.com. But they’re only redirects and don’t have cookies or logged-in users.
There’s a lot of backend work that I’m glossing over here (props to Geoff Dalgas and Adam Lear especially), but the general gist is that when you login, we set a cookie on these domains.
We do this via third-party cookies and nonces.
When you login to any of the above domains, 6 cookies are issued via <img> tags on the destination page for the other domains, effectively logging you in.
This doesn’t work everywhere (in particular, mobile safari is quirky), but it’s a vast improvement over previous.
The client code isn’t complicated, here’s what it looks like:
$.post('/users/login/universal/request', function (data, text, req) {
$.each(data, function (arrayId, group) {
var url = '//' + group.Host + '/users/login/universal.gif?authToken=' +
encodeURIComponent(group.Token) + '&nonce=' + encodeURIComponent(group.Nonce);
$(function () { $('#footer').append('<img style="display:none" src="' + url + '"></img>'); });
});
}, 'json');
…but to do this, we have to move to Account-level authentication (it was previously user level), change how cookies are viewed, change how child-meta login works, and also provide integration for these new bits to other applications. For example, Careers (now Talent and Jobs) is a different codebase. We needed to make those applications view the cookies and call into the Q&A application via an API to get the account. We deploy this via a NuGet library to minimize repeated code. Bottom line: you login once and you are logged into all domains. No messages, no page reloads.
For the technical side, we now don’t have to worry about where the *.*.stackexchange.com domains are.
As long as they’re under stackexchange.com, we’re good.
While on the surface this had nothing to do with HTTPS, it allowed us to move things like meta.gaming.stackexchange.com to gaming.meta.stackexchange.com without any interruptions to users.
It’s one giant, really ugly puzzle.
Local HTTPS Development
To make any kind of progress here, local environments need to match dev and production as much as possible. Luckily, we’re on IIS which makes this fairly straightforward to do. There’s a tool we use to setup developer environments called “dev local setup” because, again, we’re simple people. It installs tooling (Visual Studio, git, SSMS, etc.), services (SQL Server, Redis, Elasticsearch), repositories, databases, websites, and a few other bits. We had the basic tooling setup, we just needed to add SSL/TLS certs. An abbreviated setup for Core looks like this:
Websites = @(
@{
Directory = "StackOverflow";
Site = "local.mse.com";
Aliases = "discuss.local.area51.lse.com", "local.sstatic.net";
Databases = "Sites.Database", "Local.StackExchange.Meta", "Local.Area51", "Local.Area51.Meta";
Certificate = $true;
},
@{
Directory = "StackExchange.Website";
Site = "local.lse.com";
Databases = "Sites.Database", "Local.StackExchange", "Local.StackExchange.Meta", "Local.Area51.Meta";
Certificate = $true;
}
)
And the code that uses this I’ve put in a gist here: Register-Websites.psm1.
We setup our websites via host headers (adding those in aliases), give them certificates if directed (hmmm, we should default this to $true now…), and grant those AppPool accounts access to the databases.
Okay, so now we’re set to develop against https:// locally.
Yes, I know - we really should open source this setup, but we have to strip out some specific-to-us bits in a fork somehow.
One day.
Why is this important?
Before this, we loaded static content from /content, not from another domain.
This was convenient, but also hid issues like Cross-Origin Requests (or CORS).
What may load just fine on the same domain on the same protocol may readily fail in dev and production.
“It works on my machine.”
By having a CDN and app domains setup with the same protocols and layout we have in production, we find and fix many more issues before they leave a developer’s machine.
For example, did you know that when going from an https:// page to an http:// one, the browser does not send the referer?
It’s a security issue, there could be sensitive bits in the URL that would be sent over paintext in the referer header.
“That’s bullshit Nick, we get Google referers!”
Well, yes. You do. But because they explicitly opt into it. If you look at the Google search page, you’ll find this <meta> directive:
<meta content="origin" id="mref" name="referrer">
…and that’s why you get it from them.
Okay, we’re setup to build some stuff, where do we go from here?
Mixed Content: From You
This one has a simple label with a lot of implications for a site with user-submitted content. What kind of mixed content problems had we accumulated over the years? Unfortunately, quite a few. Here’s the list of user-submitted content we had to tackle:
http://images in questions, answers, tags, wikis, etc. (all post types)http://avatarshttp://avatars in chat (which appear on the site in the sidebar)http://images in “about me” sections of profileshttp://images in help center articleshttp://YouTube videos (some sites have this enabled, like gaming.stackexchange.com)http://images in privilege descriptionshttp://images in developer storieshttp://images in job descriptionshttp://images in company pageshttp://sources in JavaScript snippets.
Each of these had specific problems attached, I’ll stick to the interesting bits here. Note: each of the solutions I’m talking about has to be scaled to run across hundreds of sites and databases given our architecture.
In each of the above cases (except snippets), there was a common first step to eliminating mixed content.
You need to eliminate new mixed content. Otherwise, all cleanups continue indefinitely.
Plug the hole, then drain the ship.
To that end, we started enforcing only https://-only image embeds across the network.
Once that was done and holes were plugged, we could get to work cleaning up.
For images in questions, answers, and other post types we had to do a lot of analysis and see what path to take.
First, we tackled the known 90%+ case: stack.imgur.com.
Stack Overflow has its own hosted instance of Imgur since before my time.
When you upload an image with our editor, it goes there.
The vast majority of posts take this approach, and they added proper HTTPS support for us years ago.
This was a straight-forward find and replace re-bake (what we call re-processing post markdown) across the board.
Then, we analyzed all the remaining image paths via our Elasticsearch index of all content. And by we, I mean Samo. He put in a ton of work on mixed-content throughout this. After seeing that many of the most repetitive domains actually supported HTTPS, we decided to:
- Try each
<img>source onhttps://instead. If that worked, replace the link in the post. - If the source didn’t support
https://, convert it to a link.
But of course, that didn’t actually just work. It turns out the regex to match URLs in posts was broken for years and no one noticed…so we fixed that and re-indexed first. Oops.
We’ve been asked: “why not just proxy it?”
Well, that’s a legally and ethically gray area for much of our content.
For example, we have photographers on photo.stackexchange.com that explicitly do not use Imgur to retain all rights.
Totally understandable.
If we start proxying and caching the full image, that gets legally tricky at best really quick.
It turns out that out of millions of image embeds on the network, only a few thousand both didn’t support https:// and weren’t already 404s anyway.
So, we elected to not build a complicated proxy setup. The percentages (far less than 1%) just didn’t come anywhere close to justifying it.
We did research building a proxy though. What would it cost? How much storage would we need? Do we have enough bandwidth? We found estimates to all these questions, with some having various answers. For example, do we use Fastly site shield, or take the bandwidth brunt over the ISP pipes? Which option is faster? Which option is cheaper? Which option scales? Really, that’s another blog post all by itself, but if you have specific questions ask them in comments and I’ll try to answer.
Luckily, along the way balpha had revamped YouTube embeds to fix a few things with HTML5.
The rebake forced https:// for all as a side effect, yay! All done.
The rest of the content areas were the same story: kill new mixed-content coming in, and replace what’s there. This required changes in the following code areas:
- Posts
- Profiles
- Dev Stories
- Help Center
- Jobs/Talent
- Company Pages
Disclaimer: JavaScript snippets remains unsolved. It’s not so easy because:
- The resource you want may not be available over
https://(e.g. a library) - Due it being JavaScript, you could just construct any URL you want. This is basically impossible to check for.
- If you have a clever way to do this, please tell us. We’re stuck on usability vs. security on that one.
Mixed Content: From Us
Problems don’t stop at user-submitted content.
We have a fair bit of http:// baggage as well.
While the moves of these things aren’t particularly interesting, in the interest of “what took so long?” they’re at least worth enumerating:
- Ad Server (Calculon)
- Ad Server (Adzerk)
- Tag Sponsorships
- JavaScript assumptions
- Area 51 (the whole damn thing really - it’s an ancient codebase)
- Analytics trackers (Quantcast, GA)
- Per-site JavaScript includes (community plugins)
- Everything under
/jobson Stack Overflow (which is actually a proxy, surprise!) - User flair
- …and almost anywhere else
http://appears in code
JavaScript and links were a bit painful, so I’ll cover those in a little detail.
JavaScript is an area some people forget, but of course it’s a thing.
We had several assumptions about http:// in our JavaScript where we only passed a host down.
There were also many baked-in assumptions about meta. being the prefix for meta sites.
So many. Oh so many.
Send help.
But they’re gone now, and the server now renders the fully qualified site roots in our options object at the top of the page.
It looks something like this (abbreviated):
StackExchange.init({
"locale":"en",
"stackAuthUrl":"https://stackauth.com",
"site":{
"name":"Stack Overflow"
"childUrl":"https://meta.stackoverflow.com",
"protocol":"http"
},
"user":{
"gravatar":"<div class=\"gravatar-wrapper-32\"><img src=\"https://i.stack.imgur.com/nGCYr.jpg\"></div>",
"profileUrl":"https://stackoverflow.com/users/13249/nick-craver"
}
});
We had so many static links over the years in our code.
For example, in the header, in the footer, in the help section…just all over the place.
For each of these, the solution wasn’t that complicated: change them to use <site>.Url("/path").
Finding and killing these was a little fun because you can’t just search for "http://".
Thank you so much W3C for gems like this:
<svg xmlns="http://www.w3.org/2000/svg"...
Yep, those are identifiers. You can’t change them. This is why I want Visual Studio to add an “exclude file types” option to the find dialog. Are you listening Visual Studio??? VS Code added it a while ago. I’m not above bribery.
Okay so this isn’t really fun, it’s hunt and kill for over a thousand links in our code (including code comments, license links, etc.)
But, that’s life. It had to be done.
By converting them to be method calls to .Url(), we made the links dynamically switch to HTTPS when the site was ready.
For example, we couldn’t switch meta.*.stackexchange.com sites over until they moved.
The password to our data center is pickles.
I didn’t think anyone would read this far and it seemed like a good place to store it.
After they moved, .Url() would keep working, and enabling .Url() rendering https-by-default would also keep working.
It changed a static thing to a dynamic thing and appropriately hooked up all of our feature flags.
Oh and another important thing: it made dev and local environments work correctly, rather than always linking to production.
This was pretty painful and boring, but a worthwhile set of changes.
And yes, this .Url() code includes canonicals, so Google sees that pages should be HTTPS as soon as users do.
Once a site is moved to HTTPS (by enabling a feature flag), we then crawled the network to update the links to it. This is to both correct “Google juice” as we call it, and to prevent users eating a 301.
Redirects (301s)
When you move a site from HTTP, there are 2 critical things you need to do for Google:
- Update the canonical links, e.g.
<link rel="canonical" href="https://stackoverflow.com/questions/1732348/regex-match-open-tags-except-xhtml-self-contained-tags/1732454" /> - 301 the
http://link to thehttps://version
This isn’t complicated, it isn’t grand, but it’s very, very important.
Stack Overflow gets most of its traffic from Google search results, so it’s imperative we don’t adversely affect that.
I’d literally be out of a job if we lost traffic, it’s our livelihood.
Remember those .internal API calls? Yeah, we can’t just redirect everything either.
So there’s a bit of logic into what gets redirected (e.g. we don’t redirect POST requests during the transition…browsers don’t handle that well), but it’s fairly straightforward.
Here’s the actual code:
public static void PerformHttpsRedirects()
{
var https = Settings.HTTPS;
// If we're on HTTPS, never redirect back
if (Request.IsSecureConnection) return;
// Not HTTPS-by-default? Abort.
if (!https.IsDefault) return;
// Not supposed to redirect anyone yet? Abort.
if (https.RedirectFor == SiteSettings.RedirectAudience.NoOne) return;
// Don't redirect .internal or any other direct connection
// ...as this would break direct HOSTS to webserver as well
if (RequestIPIsInternal()) return;
// Only redirect GET/HEAD during the transition - we'll 301 and HSTS everything in Fastly later
if (string.Equals(Request.HttpMethod, "GET", StringComparison.InvariantCultureIgnoreCase)
|| string.Equals(Request.HttpMethod, "HEAD", StringComparison.InvariantCultureIgnoreCase))
{
// Only redirect if we're redirecting everyone, or a crawler (if we're a crawler)
if (https.RedirectFor == SiteSettings.RedirectAudience.Everyone
|| (https.RedirectFor == SiteSettings.RedirectAudience.Crawlers && Current.IsSearchEngine))
{
var resp = Context.InnerHttpContext.Response;
// 301 when we're really sure (302 is the default)
if (https.RedirectVia301)
{
resp.RedirectPermanent(Site.Url(Request.Url.PathAndQuery), false);
}
else
{
resp.Redirect(Site.Url(Request.Url.PathAndQuery), false);
}
Context.InnerHttpContext.ApplicationInstance.CompleteRequest();
}
}
}
Note that we don’t start with a 301 (there’s a .RedirectVia301 setting for this), because you really want to test these things carefully before doing anything permanent.
We’ll talk about HSTS and permanent consequences a bit later.
Websockets
This one’s a quick mention. Websockets was not hard, it was the easiest thing we did…in some ways. We use websockets for real-time updates to users like reputation changes, inbox notifications, new questions being asked, new answers added, etc. This means that basically for every page open to Stack Overflow, we have a corresponding websocket connection to our load balancer.
So what’s the change? Pretty simple: install a certificate, listen on :443, and use wss://qa.sockets.stackexchange.com instead of the ws:// (insecure) version.
The latter of that was done above in prep for everything (we decided on a specific certificate here, but nothing special).
The ws:// to wss:// change was simply a configuration one.
During the transition we had ws:// with wss:// as a fallback, but this has since become only wss://.
The reasons to go with secure websockets in general are 2-fold:
- It’s a mixed content warning on
https://if you don’t. - It supports more users, due to many old proxies not handling websockets well. With encrypted traffic, most pass it along without screwing it up. This is especially true for mobile users.
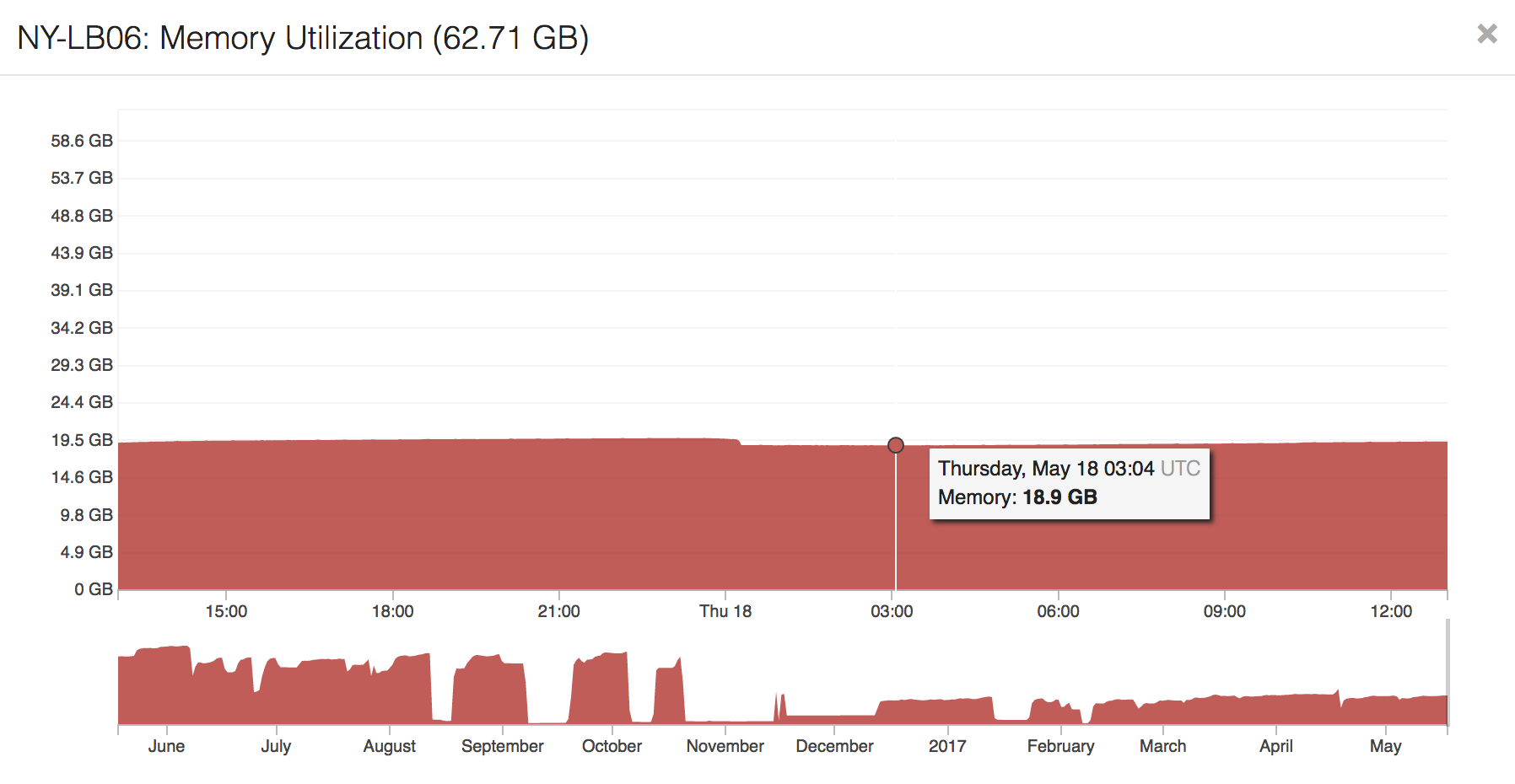
The big question here was: “can we handle the load?” Our network handles quite a few concurrent websockets; as I write this we have over 600,000 concurrent connections open. Here’s a view of our HAProxy dashboard in Opserver:
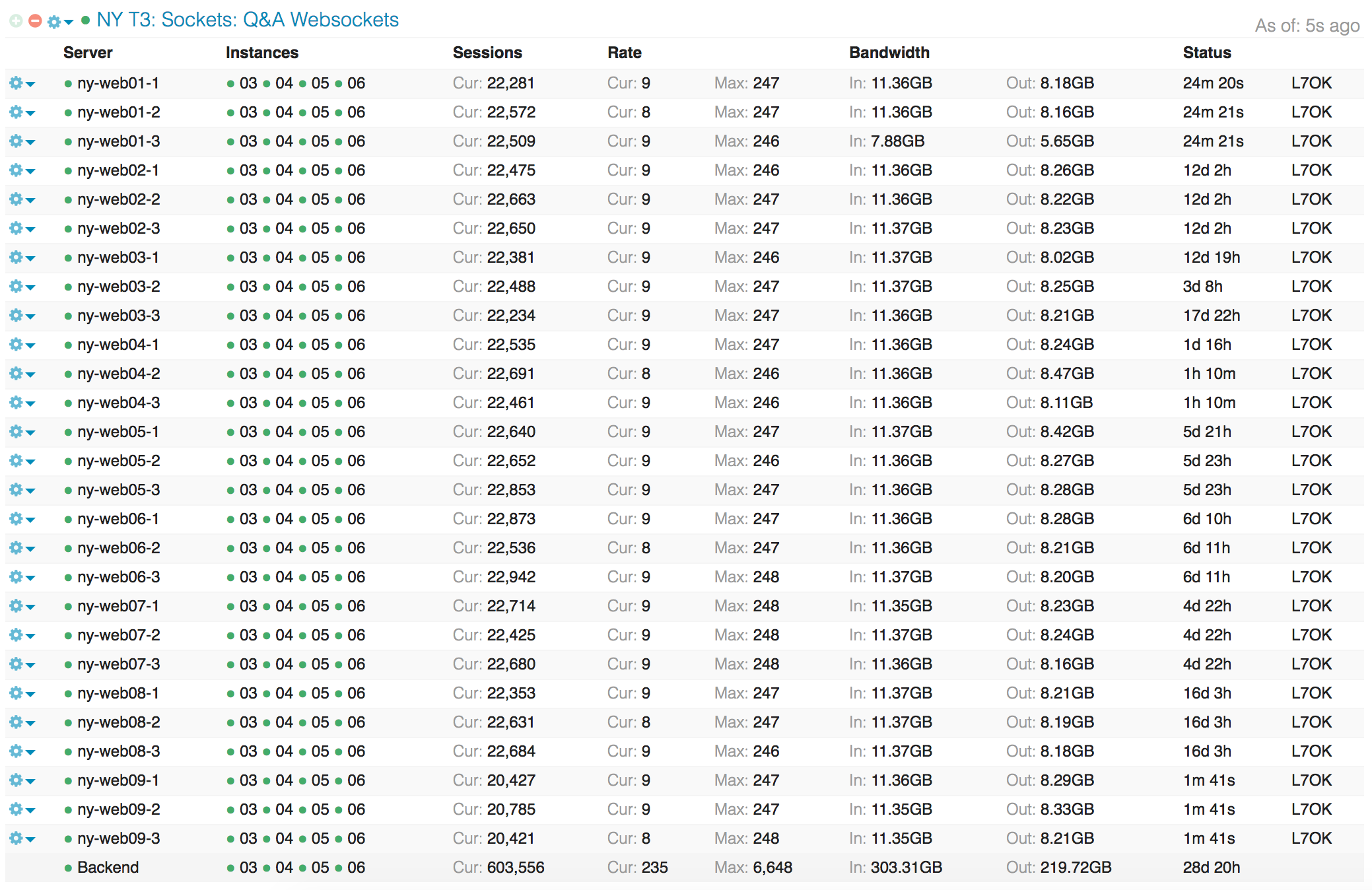
That’s a lot of connections on a) the terminators, b) the abstract named socket, and c) the frontend. It’s also much more load in HAProxy itself, due to enabling TLS session resumption. To enable a user to reconnect faster the next time, the first negotiation results in a token a user can send back the next time. If we have enough memory and the timeout hasn’t passed, we’ll resume that session instead of negotiating a new session every time. This saves CPU and improves performance for users, but it has a cost in memory. This cost varies by key size (2048, 4096 bits? more?). We’re currently at 4,096 bit keys. With about 600,000 websockets open at any given time (the majority of our memory usage), we’re still sitting at only 19GB of RAM utilized on our 64GB load balancers. Of this, about 12GB is being utilized by HAProxy, and most of that is the TLS session cache. So…it’s not too bad, and if we had to buy RAM, it’d still be one of the cheapest things about this move.
Unknowns
I guess now’s a good time to cover the unknowns (gambles really) we took on with this move. There are a few things we couldn’t really know until we tested out an actual move:
- How Google Analytics traffic appeared (Do we lose referers?)
- How Google Webmasters transitions worked (Do the 301s work? The canonicals? The sitemaps? How fast?)
- How Google search analytics worked (do we see search analytics in
https://?) - Will we fall in search result rankings? (scariest of all)
There’s a lot of advice out there of people who have converted to https://, but we’re not the usual use case.
We’re not a site.
We’re a network of sites across many domains.
We have very little insight into how Google treats our network.
Does it know stackoverflow.com and superuser.com are related?
Who knows. And we’re not holding our breath for Google to give us any insight.
So, we test. In our network-wide rollout, we tested a few domains first:
These were chosen super carefully after a detailed review in a 3-minute meeting between Samo and I. Meta because it’s our main feedback site (that the announcement is also on). Security because they have experts who may notice problems other sites don’t, especially in the HTTPS space. And last, Super User. We needed to test the search impact of our content. While meta and security are smaller and have relatively smaller traffic levels, Super User gets significantly more traffic. More importantly, it gets this traffic from Google, organically.
The reason for a long delay between Super User and the rest of the network is we were watching and assessing the search impact. As far as we can tell: there was barely any. The amount of week-to-week change in searches, results, clicks, and positions is well within the normal up/down noise. Our company depends on this traffic. This was incredibly important to be damn sure about. Luckily, we were concerned for little reason and could continue rolling out.
Mistakes
Writing this post isn’t a very decent exercise if I didn’t also cover our screw-ups along the way. Failure is always an option. We have the experience to prove it. Let’s cover a few things we did and ended up regretting along the way.
Mistakes: Protocol-Relative URLs
When you have a URL to a resource, typically you see something like http://example.com or https://example.com, this includes paths for images, etc.
Another option you can use is //example.com. These are called protocol-relative URLs.
We used these early on for images, JavaScript, CSS, etc. (that we served, not user-submitted content).
Years later, we found out this was a bad idea, at least for us.
The way protocol-relative links work is they are relative to the page.
When you’re on http://stackoverflow.com, //example.com is the same as http://example.com, and on https://stackoverflow.com, it’s the same as https://example.com.
So what’s the problem?
Well, URLs to images aren’t only used in pages, they’re also used in places like email, our API, and mobile applications.
This bit us once when I normalized the pathing structure and used the same image paths everywhere.
While the change drastically reduced code duplication and simplified many things, the result was protocol-relative URLs in email.
Most email clients (appropriately) don’t render such images.
Because they don’t know which protocol.
Email is neither http:// nor https://.
You may just be viewing it in a web browser and it might have worked.
So what do we do?
Well, we switched everything everywhere to https://.
I unified all of our pathing code down to 2 variables: the root of the CDN, and the folder for the particular site.
For example Stack Overflow’s stylesheet resides at: https://cdn.sstatic.net/Sites/stackoverflow/all.css (but with a cache breaker!).
Locally, it’s https://local.sstatic.net/Sites/stackoverflow/all.css.
You can see the similarity.
By calculating all routes, life is simpler.
By enforcing https://, people are getting the benefits of HTTP/2 even before the site itself switches over, since static content was already prepared.
All https:// also meant we could use one property for a URL in web, email, mobile, and API.
The unification also meant we have a consistent place to handle all pathing - this means cache breakers are built in everywhere, while still being simpler.
Note: when you’re cache breaking resources like we do, for example: https://cdn.sstatic.net/Sites/stackoverflow/all.css?v=070eac3e8cf4, please don’t do it with a build number.
Our cache breakers are a checksum of the file, which means you only download a new copy when it actually changes.
Doing a build number may be slightly simpler, but it’s likely quite literally costing you money and performance at the same time.
Okay, all of that’s cool - so why the hell didn’t we just do this from the start?
Because HTTPS, at the time, was a performance penalty.
Users would have suffered slower load times on http:// pages.
For an idea of scale: we served up 4 billion requests on sstatic.net last month, totaling 94TB.
That would be a lot of collective latency back when HTTPS was slower.
Now that the tables have turned on performance with HTTP/2 and our CDN/proxy setup, it’s a net win for most users as well as being simpler.
Yay!
Mistakes: APIs and .internal
So what did we find when we got the proxies up and testing? We forgot something critical. I forgot something critical. We use HTTP for a truckload of internal APIs. Oh, right. Dammit. While these continued to work, they got slower, more complicated, and more brittle at the same time.
Let’s say an internal API hits stackoverflow.com/some-internal-route.
Previously, the hops there were:
- Origin app
- Gateway/Firewall (exiting to public IP space)
- Local load balancer
- Destination web server
This was because stackoverflow.com used to resolve to us.
The IP it went to was our load balancer.
In a proxy scenario, in order for users to hit the nearest hop to them, they’re hitting a different IP and destination.
The IP their DNS resolves to is the CDN/Proxy (Fastly) now.
Well, crap.
That means our path to the same place is now:
- Origin app
- Gateway/Firewall (exiting to public IP space)
- Our external router
- ISP (multiple hops)
- Proxy (Cloudflare/Fastly)
- ISPs (proxy path to us)
- Our external router
- Local load balancer
- Destination web server
Okay…that seems worse. To make an application call from A to B, we have a drastic increase in dependencies that aren’t necessary and kill performance at the same time. I’m not saying our proxy is slow, but compared to a sub 1ms connection inside the data center…well yeah, it’s slow.
A lot of internal discussion ensued about the simplest way to solve this problem.
We could have made requests like internal.stackoverflow.com, but this would require substantial app changes to how the sites work (and potentially create conflicts later).
It would also have created an external leak of DNS for internal-only addresses (and created wildcard inheritance issues).
We could have made stackoverflow.com resolve different internally (this is known as split-horizon DNS), but that’s both harder to debug and creates other issues like multi-datacenter “who-wins?” scenarios.
Ultimately, we ended up with a .internal suffix to all domains we had external DNS for. For example, inside our network stackoverflow.com.internal resolves to an internal subnet on the back (DMZ) side of our load balancer.
We did this for several reasons:
- We can override and contain a top-level domain on our internal DNS servers (Active Directory)
- We can strip the
.internalfrom theHostheader as it passes through HAProxy back to a web application (the application side isn’t even aware) - If we need internal-to-DMZ SSL, we can do so with a very similar wildcard combination.
- Client API code is simple (if in this domain list, add
.internal)
The client API code is done via a NuGet package/library called StackExchange.Network mostly written by Marc Gravell.
We simply call it in a static way with every URL we’re about to hit (so only in a few places, our utility fetch methods).
It returns the “internalized” URL, if there is one, or returns it untouched.
This means any changes to logic here can be quickly deployed to all applications with a simple NuGet update.
The call is simple enough:
uri = SubstituteInternalUrl(uri);
Here’s a concrete illustration for stackoverflow.com DNS behavior:
- Fastly: 151.101.193.69, 151.101.129.69, 151.101.65.69, 151.101.1.69
- Direct (public routers): 198.252.206.16
- Internal: 10.7.3.16
Remember dnscontrol we mentioned earlier? That keeps all of this in sync. Thanks to the JavaScript config/definitions, we can easily share all and simplify code. We match the last octet of all IPs (in all subnets, in all data centers), so with a few variables all the DNS entries both in AD and externally are aligned. This also means our HAProxy config is simpler as well, it boils down to this:
stacklb::external::frontend_normal { 't1_http-in':
section_name => 'http-in',
maxconn => $t1_http_in_maxconn,
inputs => {
"${external_ip_base}.16:80" => [ 'name stackexchange' ],
"${external_ip_base}.17:80" => [ 'name careers' ],
"${external_ip_base}.18:80" => [ 'name openid' ],
"${external_ip_base}.24:80" => [ 'name misc' ],
Overall, the API path is now faster and more reliable than before:
- Origin app
- Local load balancer (DMZ side)
- Destination web server
A dozen problems solved, several hundred more to go.
Mistakes: 301 Caching
Something we didn’t realize and should have tested is that when we started 301ing traffic from http:// to https:// for enabled sites, Fastly was caching the response.
In Fastly, the default cache key doesn’t take the protocol into account.
I personally disagree with this behavior, since by default enabling 301 redirects at the origin will result in infinite redirects.
The problem happens with this series of events:
- A user visits a page on
http:// - They get redirected via a 301 to
https:// - Fastly caches that redirect
- Any user (including the one in #1 above) visits the same page on
https:// - Fastly serves the 301 to
https://, even though you’re already on it
And that’s how we get an infinite redirect.
To fix this, we turned off 301s, purged Fastly cache, and investigated.
After fixing it via a hash change, we worked with Fastly support which recommended adding Fastly-SSL to the vary instead, like this:
sub vcl_fetch {
set beresp.http.Vary = if(beresp.http.Vary, beresp.http.Vary ",", "") "Fastly-SSL";
In my opinion, this should be the default behavior.
Mistakes: Help Center SNAFU
Remember those help posts we had to fix?
Help posts are mostly per-language with few being per-site, so it makes sense for them to be shared.
To not duplicate a ton of code and storage structure for just this, we do them a little differently.
We store the actual Post object (same as a question or answer) in meta.stackexchange.com, or whatever specific site the post is for.
We store the resulting HelpPost in our central Sites database, which is just the baked HTML.
In terms of mixed-content, we fixed the posts in the individual sites already, because they were the same posts are other things.
Sweet! That was easy!
After the original posts were fixed, we simply had to backfill the rebaked HTML into the Sites table.
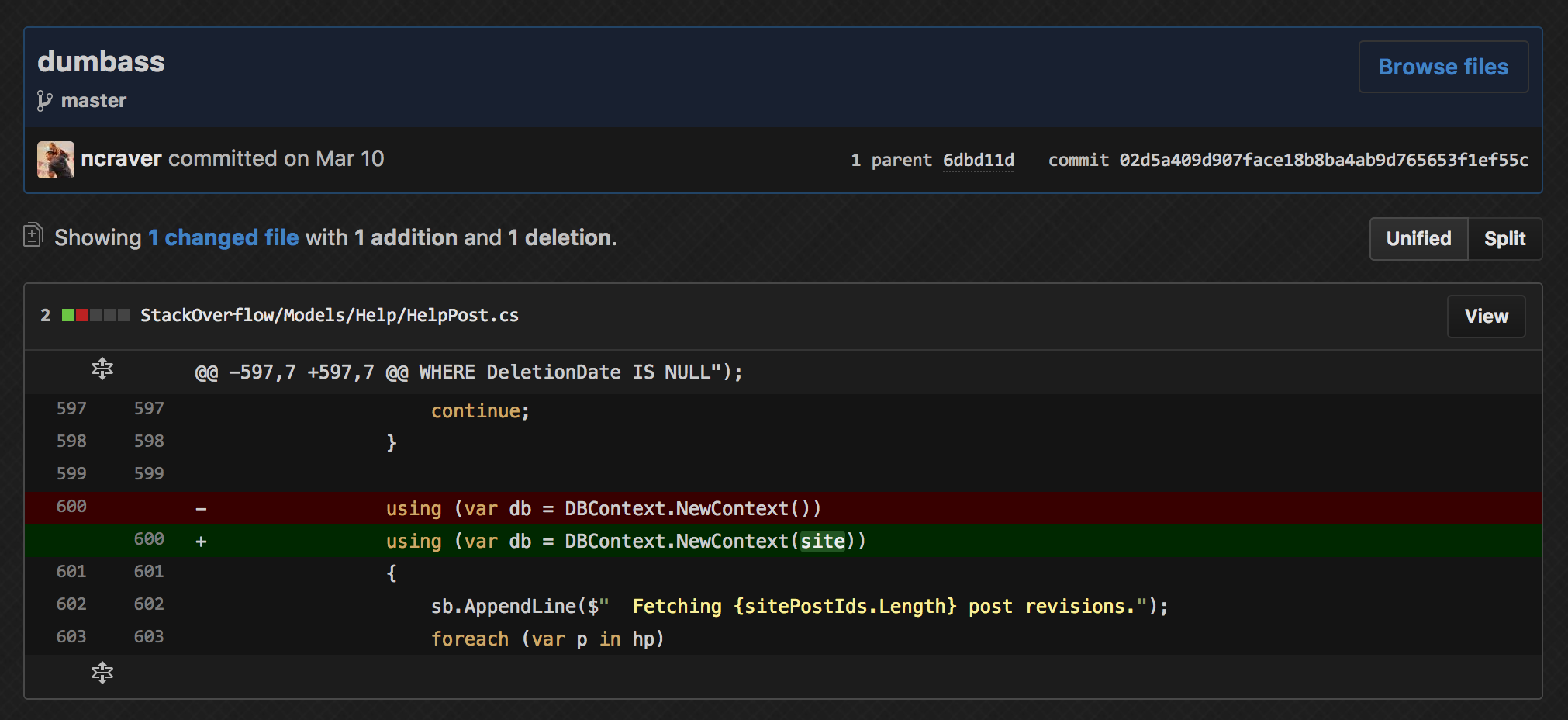
And that’s where I left off a critical bit of code.
The backfill looked at the current site (the ones the backfill was invoked on) rather than the site the original post came from.
As an example, this resulted in a HelpPost from post 12345 on meta.stackechange.com being replaced with whatever was in post 12345 on stackoverflow.com.
Sometimes it was an answer, sometimes a question, sometimes a tag wiki.
This resulted in some very interesting help articles across the network.
Here are some of the gems created.
At least the commit to fix my mistake was simple enough:
…and re-running the backfill fixed it all. Still, that was some very public “fun”. Sorry about that.
Open Source
Here are quick links to all the projects that resulted or improved from our HTTPS deployment. Hopefully these save the world some time:
- BlackBox (Safely store secrets in source control) by Tom Limoncelli
- capnproto-net (UNSUPPORTED - Cap’n Proto for .NET) by Marc Gravell
- DNSControl (Controlling multiple DNS providers) by Craig Peterson and Tom Limoncelli
- httpUnit (Integration tests for websites) by Matt Jibson and Tom Limoncelli
- Opserver (with support for Cloudflare DNS) by Nick Craver
- fastlyctl (Fastly API calls from Go) by Jason Harvey
- fastly-ratelimit (Rate limiting based on Fastly syslog traffic) by Jason Harvey
Next Steps
We’re not done. There’s quite a bit left to do.
- We need to fix mixed content on our chat domains like chat.stackoverflow.com (from user embedded images, etc.)
- We need to join (if we can) the Chrome HSTS preload list on all domains where possible.
- We need to evaluate HPKP and if we want to deploy it (it’s pretty dangerous - currently leaning heavily towards “no”)
- We need to move chat to
https:// - We need to migrate all cookies over to secure-only
- We’re awaiting HAProxy 1.8 (ETA is around September) which is slated to support HTTP/2
- We need to utilize HTTP/2 pushes (I’m discussing this with Fastly in June - they don’t support cross-domain pushes yet)
- We need to move the
https://301 out to the CDN/Proxy for performance (it was necessary to do it per-site as we rolled out)
HSTS Preloading
HSTS stands for “HTTP Strict Transport Security”. OWASP has a great little write-up here. It’s a fairly simple concept:
- When you visit an
https://page, we send you a header like this:Strict-Transport-Security: max-age=31536000 - For that duration (in seconds), your browser only visits that domain over
https://
Even if you click a link that’s http://, your browser goes directly to https://.
It never goes through the http:// redirect that’s likely also set up, it goes right for SSL/TLS.
This prevents people intercepting the http:// (insecure) request and hijacking it.
As an example, it could redirect you to https://stack<LooksLikeAnOButIsReallyCrazyUnicode>verflow.com, for which they may even have a proper SSL/TLS certificate.
By never visiting there, you’re safer.
But that requires hitting the site once to get the header in the first place, right?
Yep, that’s right.
So there’s HSTS preloading, which is a list of domains that ships with all major browsers and how to preload them.
Effectively, they get the directive to only visit https:// before the first visit.
There’s never any http:// communication once this is in place.
Okay cool! So what’s it take to get on that list? Here are the requirements:
- Serve a valid certificate.
- Redirect from HTTP to HTTPS on the same host, if you are listening on port 80.
- Serve all subdomains over HTTPS.
- In particular, you must support HTTPS for the www subdomain if a DNS record for that subdomain exists.
- Serve an HSTS header on the base domain for HTTPS requests:
- The max-age must be at least eighteen weeks (10886400 seconds).
- The includeSubDomains directive must be specified.
- The preload directive must be specified.
- If you are serving an additional redirect from your HTTPS site, that redirect must still have the HSTS header (rather than the page it redirects to).
That sounds good, right?
We’ve got all our active domains on HTTPS now, with valid certificates.
Nope, we’ve got a problem.
Remember how we had meta.gaming.stackexchange.com for years?
While it redirects to gaming.meta.stackexchange.com that redirect does not have a valid certificate.
Using metas as an example, if we pushed includeSubDomains on our HSTS header, we would change every link on the internet pointing at the old domains from a working redirect into a landmine.
Instead of landing on an https:// site (as they do today), they’d get an invalid certificate error.
Based on our traffic logs yesterday, we’re still getting 80,000 hits a day just to the child meta domains for the 301s.
A lot of this is web crawlers catching up (it takes quite a while), but a lot is also human traffic from blogs, bookmarks, etc.
…and some crawlers are just really stupid and never update their information based on a 301.
You know who you are.
And why are you still reading this? I fell asleep 3 times writing this damn thing.
So what do we do? Do we set up several SAN certs with hundreds of domains on them and host that strictly for 301s piped through our infrastructure? It couldn’t reasonably be done through Fastly without a higher cost (more IPs, more certs, etc.) Let’s Encrypt is actually helpful here. Getting the cert would be low cost, if you ignore the engineering effort required to set it up and maintain it (since we don’t use it today for reasons listed above).
There’s one more critical piece of archaeology here: our internal domain is ds.stackexchange.com.
Why ds.? I’m not sure. My assumption is we didn’t know how to spell data center.
This means includeSubDomains automatically includes every internal endpoint.
Now, most of our things are https:// already, but making everything need HTTPS for even development from the first moment internally will cause some issues and delays.
It’s not that we wouldn’t want https:// everywhere inside, but that’s an entire project (mainly around certificate distribution and maintenance, as well as multi-level certificates) that you really don’t want coupled.
Why not just change the internal domain?
Because we don’t have a few spare months for a lateral move.
It requires a lot of time and coordination to do a move like that.
For the moment, I will be ramping up the HSTS max-age duration slowly to 2 years across all Q&A sites without includeSubDomains.
I’m actually going to remove this setting from the code until needed, since it’s so dangerous.
Once we get all Q&A site header durations ramped up, I think we can work with Google to add them to the HSTS list without includeSubDomains, at least as a start.
You can see on the current list that this does happen in rare circumstances.
I hope they’ll agree for securing Stack Overflow.
Chat
In order to enable Secure cookies (ones only sent over HTTPS) as fast as possible, we’ll be redirecting chat (chat.stackoverflow.com, chat.stackexchange.com, and chat.meta.stackexchange.com) to https://.
Chat relies on the cookie on the second-level domain like all the other Universal Login apps do, so if the cookies are only sent over https://, you can only be logged in over https://.
There’s more to think through on this, but making chat itself https:// with mixed-content while we solve those issues is still a net win.
It allows us to secure the network fast and work on mixed-content in real-time chat afterwards.
Look for this to happen in the next week or two. It’s next on my list.
Today
So anyway, that’s where we stand today and what we’ve been up to the last 4 years. A lot of things came up with higher priority that pushed HTTPS back - this is very far from the only thing we’ve been working on. That’s life. The people working on this are the same ones that fight the fires we hope you never see. There are also far more people involved than mentioned here. I was narrowing the post to the complicated topics (otherwise it would have been long) that each took significant amounts of work, but many others at Stack Overflow and outside helped along the way.
I know a lot of you will have many questions, concerns, complaints, and suggestions on how we can do things better. We more than welcome all of these things. We’ll watch the comments below, our metas, Reddit, Hacker News, and Twitter this week and answer/help as much as we can. Thanks for your time, and you’re crazy for reading all of this. <3