Stack Overflow: How We Do Deployment - 2016 Edition
This is #3 in a very long series of posts on Stack Overflow’s architecture.
Previous post (#2): Stack Overflow: The Hardware - 2016 Edition
We’ve talked about Stack Overflow’s architecture and the hardware behind it. The next most requested topic was Deployment. How do we get code a developer (or some random stranger) writes into production? Let’s break it down. Keep in mind that we’re talking about deploying Stack Overflow for the example, but most of our projects follow almost an identical pattern to deploy a website or a service.
I’m going ahead and inserting a set of section links here because this post got a bit long with all of the bits that need an explanation:
- Source & Context
- The Human Steps
- Branches
- Git On-Premises
- The Build System
- What’s In The Build?
- Tiers
- Database Migrations
- Localization/Translations (Moonspeak)
- Building Without Breaking
- Extra resources because I love you all
Source
This is our starting point for this article. We have the Stack Overflow repository on a developer’s machine. For the sake of discussing the process, let’s say they added a column to a database table and the corresponding property to the C# object — that way we can dig into how database migrations work along the way.
A Little Context
We deploy roughly 25 times per day to development (our CI build) just for Stack Overflow Q&A. Other projects also push many times. We deploy to production about 5-10 times on a typical day. A deploy from first push to full deploy is under 9 minutes (2:15 for dev, 2:40 for meta, and 3:20 for all sites). We have roughly 15 people pushing to the repository used in this post. The repo contains the code for these applications: Stack Overflow (every single Q&A site), stackexchange.com (root domain only), Stack Snippets (for Stack Overflow JavaScript snippets), Stack Auth (for OAuth), sstatic.net (cookieless CDN domain), Stack Exchange API v2, Stack Exchange Mobile (iOS and Android API), Stack Server (Tag Engine and Elasticsearch indexing Windows service), and Socket Server (our WebSocket Windows service).
The Human Steps
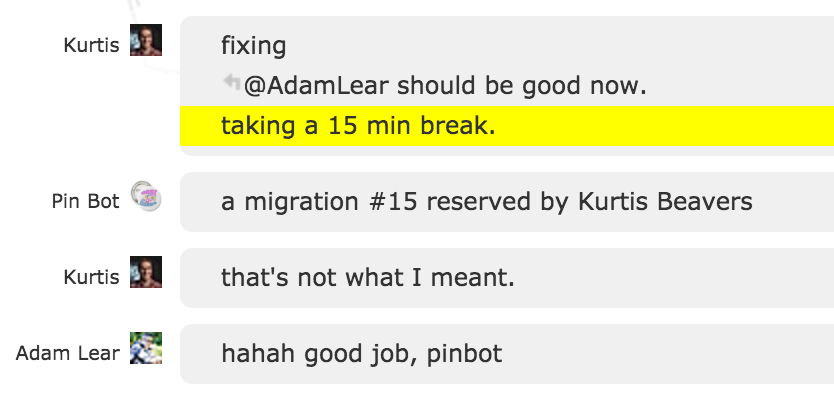
When we’re coding, if a database migration is involved then we have some extra steps. First, we check the chatroom (and confirm in the local repo) which SQL migration number is available next (we’ll get to how this works). Each project with a database has their own migration folder and number. For this deploy, we’re talking about the Q&A migrations folder, which applies to all Q&A databases. Here’s what chat and the local repo look like before we get started:

And here’s the local %Repo%\StackOverflow.Migrations\ folder:

You can see both in chat and locally that 726 was the last migration number taken. So we’ll issue a “taking 727 - Putting JSON in SQL to see who it offends” message in chat. This will claim the next migration so that we don’t collide with someone else also doing a migration. We just type a chat message, a bot pins it. Fun fact: it also pins when I say “taking web 2 offline”, but we think it’s funny and refuse to fix it. Here’s our little Pinbot trolling:
Now let’s add some code — we’ll keep it simple here:
A \StackOverflow\Models\User.cs diff:
+ public string PreferencesJson { get; set; }And our new \StackOverflow.Migrations\727 - Putting JSON in SQL to see who it offends.sql:
If dbo.fnColumnExists('Users', 'PreferencesJson') = 0
Begin
Alter Table Users Add PreferencesJson nvarchar(max);
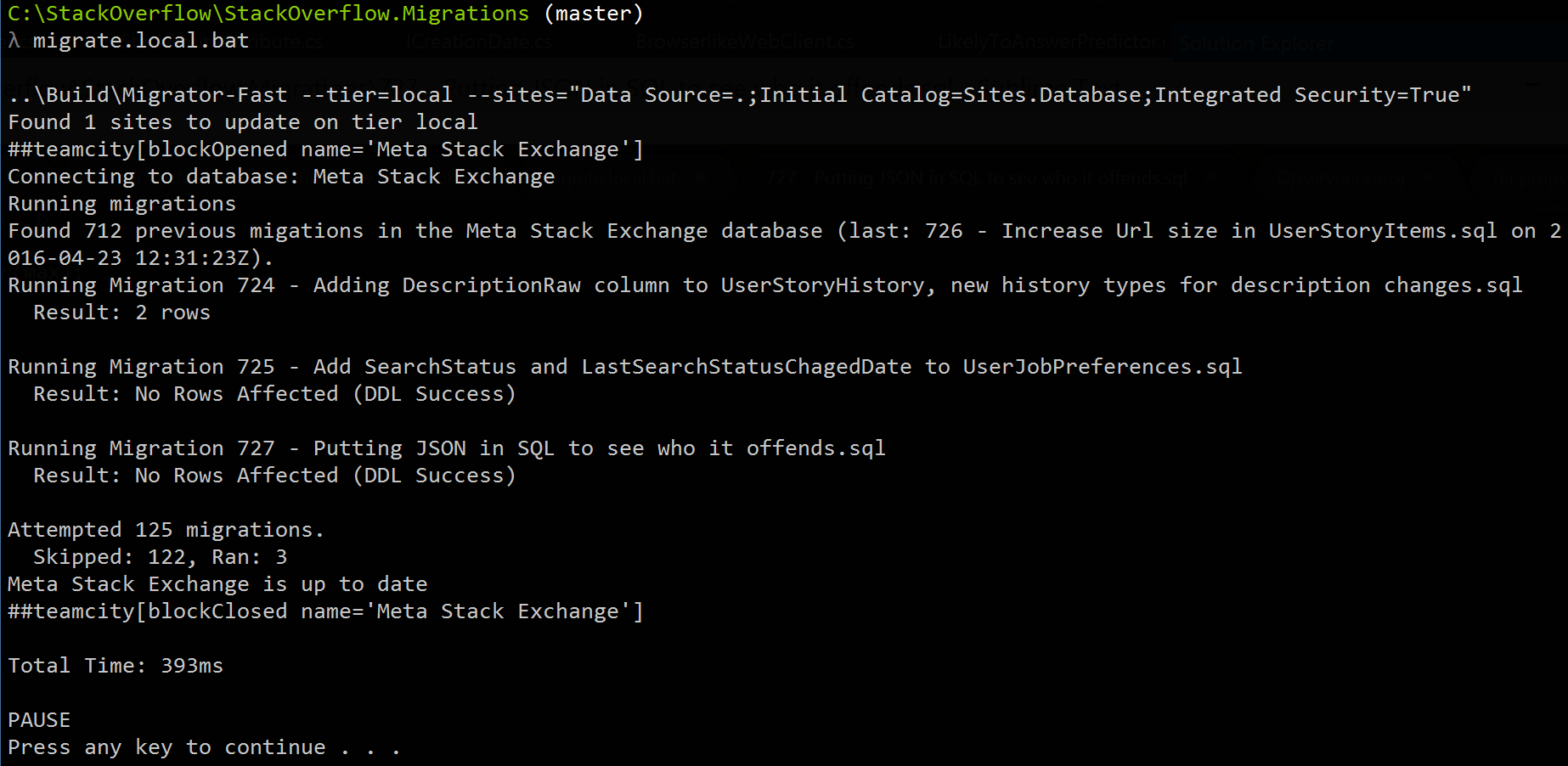
EndWe’ve tested the migration works by running it against our local Q&A database of choice in SSMS and that the code on top of it works. Before deploying though, we need to make sure it runs as a migration. For example, sometimes you may forget to put a GO separating something that must be the first or only operation in a batch such as creating a view. So, we test it in the runner. To do this, we run the migrate.local.bat you see in the screenshot above. The contents are simple:
..\Build\Migrator-Fast --tier=local
--sites="Data Source=.;Initial Catalog=Sites.Database;Integrated Security=True" %*
PAUSENote: the migrator is a project, but we simply drop the .exe in the solutions using it, since that’s the simplest and most portable thing that works.
What does this migrator do? It hits our local copy of the Sites database. It contains a list of all the Q&A sites that developer runs locally and the migrator uses that list to connect and run all migrations against all databases, in Parallel. Here’s what a run looks like on a simple install with a single Q&A database:
So far, so good. We have code and a migration that works and code that does…some stuff (which isn’t relevant to this process). Now it’s time to take our little code baby and send it out into the world. It’s time to fly little code, be freeeeee! Okay now that we’re excited, the typical process is:
git add <files> (usually --all for small commits)
git commit -m "Migration 727: Putting JSON in SQL to see who it offends"
git pull --rebase
git pushNote: we first check our team chatroom to see if anyone is in the middle of a deploy. Since our deployments are pretty quick, the chances of this aren’t that big. But, given how often we deploy, collisions can and do happen. Then we yell at the designer responsible.
With respect to the Git commands above: if a command line works for you, use it. If a GUI works for you, use it. Use the best tooling for you and don’t give a damn what anyone else thinks. The entire point of tooling from an ancient hammer to a modern Git install is to save time and effort of the user. Use whatever saves you the most time and effort. Unless it’s Emacs, then consult a doctor immediately.
Branches
I didn’t cover branches above because compared to many teams, we very rarely use them. Most commits are on master. Generally, we branch for only one of a few reasons:
- A developer is new, and early on we want code reviews
- A developer is working on a big (or risky) feature and wants a one-off code review
- Several developers are working on a big feature
Other than the (generally rare) cases above, almost all commits are directly to master and deployed soon after. We don’t like a big build queue. This encourages us to make small to medium size commits often and deploy often. It’s just how we choose to operate. I’m not recommending it for most teams or any teams for that matter. Do what works for you. This is simply what works for us.
When we do branch, merging back in is always a topic people are interested in. In the vast majority of cases, we’ll squash when merging into master so that rolling back the changes is straightforward. We also keep the original branch around a few days (for anything major) to ensure we don’t need to reference what that specific change was about. That being said, we’re practical. If a squash presents a ton of developer time investment, then we just eat the merge history and go on with our lives.
Git On-Premises
Alright, so our code is sent to the server-side repo. Which repo? We’re currently using Gitlab for repositories. It’s pretty much GitHub, hosted on-prem. If Gitlab pricing keeps getting crazier (note: I said “crazier”, not “more expensive”), we’ll certainly re-evaluate GitHub Enterprise again.
Why on-prem for Git hosting? For the sake of argument, let’s say we used GitHub instead (we did evaluate this option). What’s the difference? First, builds are slower. While GitHub’s protocol implementation of Git is much faster, latency and bandwidth making the builds slower than pulling over 2x10Gb locally. But to be fair, GitHub is far faster than Gitlab at most operations (especially search and viewing large diffs).
However, depending on GitHub (or any offsite third party) has a few critical downsides for us. The main downside is the dependency chain. We aren’t just relying on GitHub servers to be online (their uptime is pretty good). We’re relying on them to be online and being able to get to them. For that matter, we’re also relying on all of our remote developers to be able to push code in the first place. That’s a lot of switching, routing, fiber, and DDoS surface area in-between us and the bare essentials needed to build: code. We can drastically shorten that dependency chain by being on a local server. It also alleviates most security concerns we have with any sensitive code being on a third-party server. We have no inside knowledge of any GitHub security issues or anything like that, we’re just extra careful with such things. Quite simply: if something doesn’t need to leave your network, the best security involves it not leaving your network.
All of that being said, our open source projects are hosted on GitHub and it works great. The critical ones are also mirrored internally on Gitlab for the same reasons as above. We have no issues with GitHub (they’re awesome), only the dependency chain. For those unaware, even this website is running on GitHub pages…so if you see a typo in this post, submit a PR.
The Build System
Once the code is in the repo, the continuous integration build takes over. This is just a fancy term for a build kicked off by a commit. For builds, we use TeamCity. The TeamCity server is actually on the same VM as Gitlab since neither is useful without the other and it makes TeamCity’s polling for changes a fast and cheap operation. Fun fact: since Linux has no built-in DNS caching, most of the DNS queries are looking for…itself. Oh wait, that’s not a fun fact — it’s actually a pain in the ass.
As you may have heard, we like to keep things really simple. We have extra compute capacity on our web tier, so…we use it. Builds for all of the websites run on agents right on the web tier itself, this means we have 11 build agents local to each data center. There are a few additional Windows and Linux build agents (for puppet, rpms, and internal applications) on other VMs, but they’re not relevant to this deploy process.
Like most CI builds, we simply poll the Git repo on an interval to see if there are changes. This repo is heavy hit, so we poll for changes every 15 seconds. We don’t like waiting. Waiting sucks. Once a change is detected, the build server instructs an agent to run a build.
Since our repos are large (we include dependencies like NuGet packages, though this is changing), we use what TeamCity calls agent-side checkout. This means the agent does the actual fetching of content directly from the repository, rather than the default of the web server doing the checkout and sending all of the source to the agent. On top of this, we’re using Git mirrors. Mirrors maintain a full repository (one per repo) on the agent. This means the very first time the agent builds a given repository, it’s a full git clone. However, every time after that it’s just a git pull. Without this optimization, we’re talking about a git clone --depth 1, which grabs the current file state and no history — just what we need for a build. With the very small delta we’ve pushed above (like most commits) a git pull of only that delta will always beat the pants off grabbing all of files across the network. That first-build cost is a no-brainer tradeoff.
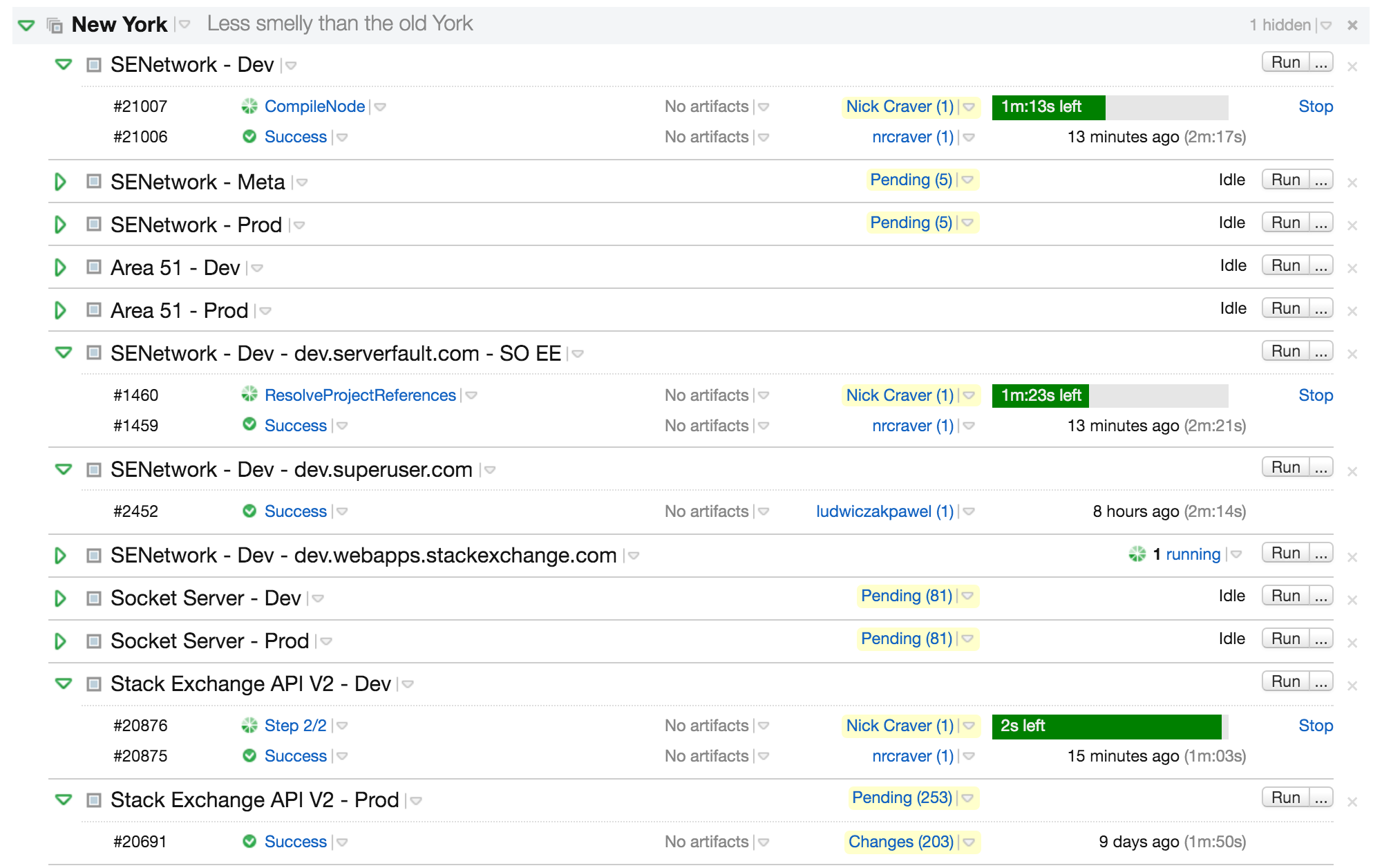
As I said earlier, there are many projects in this repo (all connected), so we’re really talking about several builds running each commit (5 total):
What’s In The Build?
Okay…what’s that build actually doing? Let’s take a top level look and break it down. Here are the 9 build steps in our development/CI build:
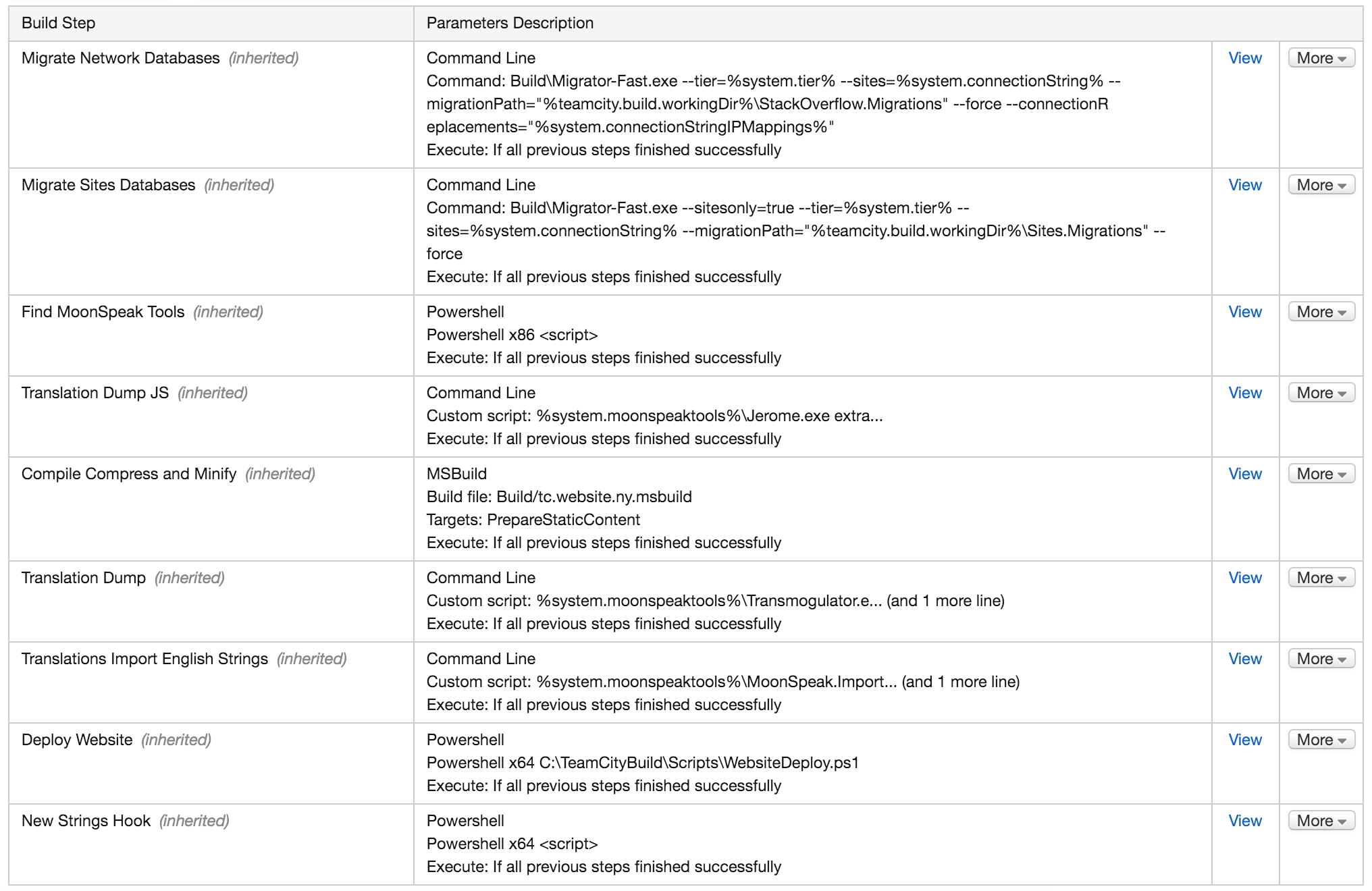
And here’s what the log of the build we triggered above looks like (you can see the full version in a gist here):
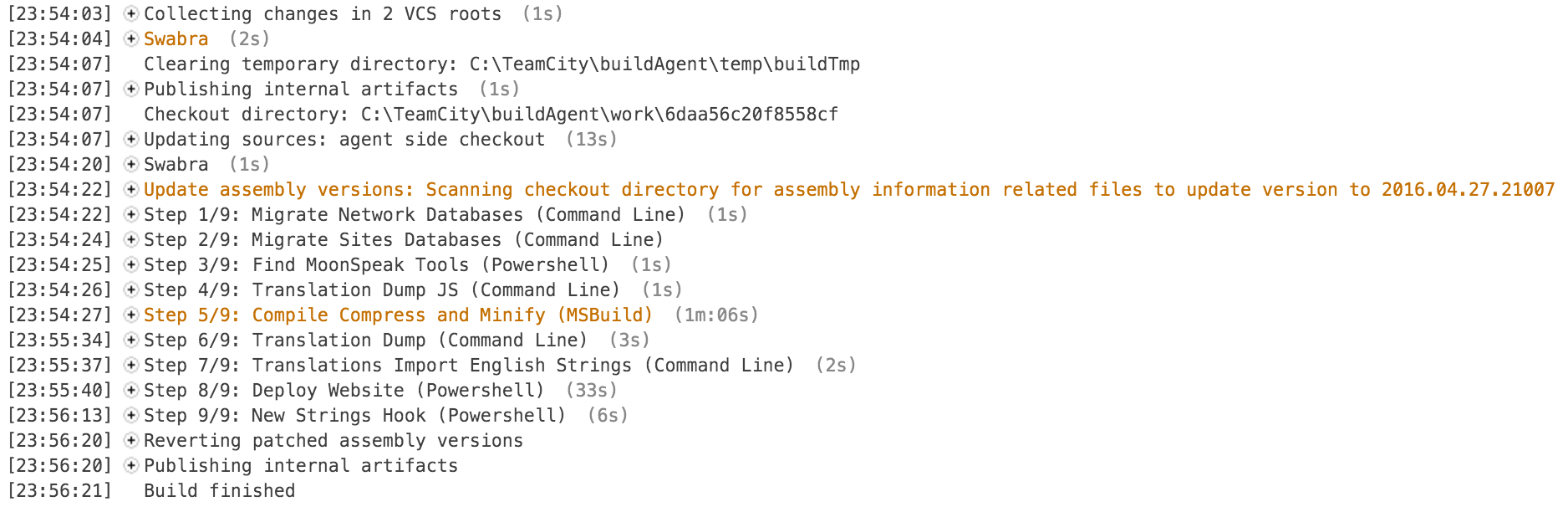
Steps 1 & 2: Migrations
The first 2 steps are migrations. In development, we automatically migrate the “Sites” database. This database is our central store that contains the master list of sites and other network-level items like the inbox. This same migration isn’t automatic in production since “should this run be before or after code is deployed?” is a 50/50 question. The second step is what we ran locally, just against dev. In dev, it’s acceptable to be down for a second, but that still shouldn’t happen. In the Meta build, we migrate all production databases. This means Stack Overflow’s database gets new SQL bits minutes before code. We order deploys appropriately.
The important part here is databases are always migrated before code is deployed. Database migrations are a topic all in themselves and something people have expressed interest in, so I detail them a bit more a little later in this post.
Step 3: Finding Moonspeak (Translation)
Due to the structure and limitations of the build process, we have to locate our Moonspeak tooling since we don’t know the location for sure (it changes with each version due to the version being in the path). Okay, what’s Moonspeak? Moonspeak is the codename for our localization tooling. Don’t worry, we’ll cover it in-depth later. The step itself is simple:
echo "##teamcity[setParameter name='system.moonspeaktools'
value='$((get-childitem -directory packages/StackExchange.MoonSpeak.2*).FullName)\tools']"It’s just grabbing a directory path and setting the system.moonspeaktools TeamCity variable to the result. If you’re curious about all of the various ways to interact with TeamCity’s build, there’s an article here.
Step 4: Translation Dump (JavaScript Edition)
In dev specifically, we run the dump of all of our need-to-be-translated strings in JavaScript for localization. Again the command is pretty simple:
%system.moonspeaktools%\Jerome.exe extract
%system.translationsDumpPath%\artifact-%build.number%-js.{0}.txt en;pt-br;mn-mn;ja;es;ru
".\StackOverflow\Content\Js\*.js;.\StackOverflow\Content\Js\PartialJS\**\*.js"Phew, that was easy. I don’t know why everyone hates localization. Just kidding, localization sucks here too. Now I don’t want to dive too far into localization because that’s a whole (very long) post on its own, but here are the translation basics:
Strings are surrounded by _s() (regular string) or _m() (markdown) in code. We love _s() and _m(). It’s almost identical for both JavaScript and C#. During the build, we extract these strings by analyzing the JavaScript (with AjaxMin) and C#/Razor (with a custom Roslyn-based build). We take these strings and stick them in files to use for the translators, our community team, and ultimately back into the build later. There’s obviously way more going on - but those are the relevant bits. It’s worth noting here that we’re excited about the proposed Source Generators feature specced for a future Roslyn release. We hope in its final form we’ll be able to re-write this portion of Moonspeak as a much simpler generator while still avoiding as many runtime allocations as possible.
Step 5: MSBuild
This is where most of the magic happens. It’s a single step, but behind the scenes, we’re doing unspeakable things to MSBuild that I’m going to…speak about, I guess. The full .msbuild file is in the earlier Gist. The most relevant section is the description of crazy:
THIS IS HOW WE ROLL:
CompileWeb - ReplaceConfigs - - - - - - BuildViews - - - - - - - - - - - - - PrepareStaticContent
\ /|
'- BundleJavaScript - TranslateJsContent - CompileNode - '
NOTE:
since msbuild requires separate projects for parallel execution of targets, this build file is copied
2 times, the DefaultTargets of each copy is set to one of BuildViews, CompileNode or CompressJSContent.
thus the absence of the DependesOnTarget="ReplaceConfigs" on those _call_ targetsWhile we maintain 1 copy of the file in the repo, during the build it actually forks into 2 parallel MSBuild processes. We simply copy the file, change the DefaultTargets, and kick it off in parallel here.
The first process is building the ASP.NET MVC views with our custom Roslyn-based build in StackExchange.Precompilation, explained by Samo Prelog here. It’s not only building the views but also plugging in localized strings for each language via switch statements. There’s a hint at how that works a bit further down. We wrote this process for localization, but it turns out controlling the speed and batching of the view builds allows us to be much faster than aspnet_compiler used to be. Rumor is performance has gotten better there lately, though.
The second process is the .less, .css, and .js compilation and minification which involves a few components. First up are the .jsbundle files. They are simple files that look like this example:
{
"items": [ "full-anon.jsbundle", "PartialJS\\full\\*.js", "bounty.js" ]
}These files are true to their name, they are simply concatenated bundles of files for use further on. This allows us to maintain JavaScript divided up nicely across many files but handle it as one file for the rest of the build. The same bundler code runs as an HTTP handler locally to combine on the fly for local development. This sharing allows us to mimic production as best we can.
After bundling, we have regular old .js files with JavaScript in them. They have letters, numbers, and even some semicolons. They’re delightful. After that, they go through the translator of doom. We think. No one really knows. It’s black magic. Really what happens here isn’t relevant, but we get a full.en.js, full.ru.js, full.pt.js, etc. with the appropriate translations plugged in. It’s the same <filename>.<locale>.js pattern for every file. I’ll do a deep-dive with Samo on the localization post (go vote it up if you’re curious).
After JavaScript translation completes (10-12 seconds), we move on to the Node.js piece of the build. Note: node is not installed on the build servers; we have everything needed inside the repo. Why do we use Node.js? Because it’s the native platform for Less.js and UglifyJS. Once upon a time we used dotLess, but we got tired of maintaining the fork and went with a node build process for faster absorption of new versions.
The node-compile.js is also in the Gist. It’s a simple forking script that sets up n node worker processes to handle the hundreds of files we have (due to having hundreds of sites) with the main thread dishing out work. Files that are identical (e.g. the beta sites) are calculated once then cached, so we don’t do the same work a hundred times. It also does things like add cache breakers on our SVG URLs based on a hash of their contents. Since we also serve the CSS with a cache breaker at the application level, we have a cache-breaker that changes from bottom to top, properly cache-breaking at the client when anything changes. The script can probably be vastly improved (and I’d welcome it), it was just the simplest thing that worked and met our requirements when it was written and hasn’t needed to change much since.
Note: a (totally unintentional) benefit of the cache-breaker calculation has been that we never deploy an incorrect image path in CSS. That situation blows up because we can’t find the file to calculate the hash…and the build fails.
The totality of node-compile’s job is minifying the .js files (in place, not something like .min.js) and turning .less into .css. After that’s done, MSBuild has produced all the output we need to run a fancy schmancy website. Or at least something like Stack Overflow. Note that we’re slightly odd in that we share styles across many site themes, so we’re transforming hundreds of .less files at once. That’s the reason for spawning workers — the number spawned scales based on core count.
Step 6: Translation Dump (C# Edition)
This step we call the transmogulator. It copies all of the to-be-localized strings we use in C# and Razor inside _s() and _m() out so we have the total set to send to the translators. This isn’t a direct extraction, it’s a collection of some custom attributes added when we translated things during compilation in the previous step. This step is just a slightly more complicated version of what’s happening in step #4 for JavaScript. We dump the files in raw .txt files for use later (and as a history of sorts). We also dump the overrides here, where we supply overrides directly on top of what our translators have translated. These are typically community fixes we want to upstream.
I realize a lot of that doesn’t make a ton of sense without going heavily into how the translation system works - which will be a topic for a future post. The basics are: we’re dumping all the strings from our codebase so that people can translate them. When they are translated, they’ll be available for step #5 above in the next build after.
Here’s the entire step:
%system.moonspeaktools%\Transmogulator.exe .\StackOverflow\bin en;pt-br;mn-mn;ja;es;ru
"%system.translationsDumpPath%\artifact-%build.number%.{0}.txt" MoonSpeak
%system.moonspeaktools%\OverrideExporter.exe export "%system.translationConnectionString%"
"%system.translationsDumpPath%"Step 7: Importing English Strings
One of the weird things to think about in localization is the simplest way to translate is to not special case English. To that end, here we are special casing it. Dammit, we already screwed up. But, by special casing it at build time, we prevent having to special case it later. Almost every string we put in would be correct in English, only needing the translation overrides for multiples and such (e.g. “1 item” vs “2 items”), so we want to immediately import anything added to the English result set so that it’s ready for Stack Overflow as soon as it’s built the first time (e.g. no delay on the translators for deploying a new feature). Ultimately, this step takes the text files created for English in Steps 4 and 6 and turns around and inserts them (into our translations database) for the English entries.
This step also posts all new strings added to a special internal chatroom alerting our translators in all languages so that they can be translated ASAP. Though we don’t want to delay builds and deploys on new strings (they may appear in English for a build and we’re okay with that), we want to minimize it - so we have an alert pipe so to speak. Localization delays are binary: either you wait on all languages or you don’t. We choose faster deploys.
Here’s the call for step 7:
%system.moonspeaktools%\MoonSpeak.Importer.exe "%system.translationConnectionString%"
"%system.translationsDumpPath%\artifact-%build.number%.en.txt" 9 false
"https://teamcity/viewLog.html?buildId=%teamcity.build.id%&tab=buildChangesDiv"
%system.moonspeaktools%\MoonSpeak.Importer.exe "%system.translationConnectionString%"
"%system.translationsDumpPath%\artifact-%build.number%-js.en.txt" 9 false
"https://teamcity/viewLog.html?buildId=%teamcity.build.id%&tab=buildChangesDiv"Step 8: Deploy Website
Here’s where all of our hard work pays off. Well, the build server’s hard work really…but we’re taking credit. We have one goal here: take our built code and turn it into the active code on all target web servers. This is where you can get really complicated when you really just need to do something simple. What do you really need to perform to deploy updated code to a web server? Three things:
- Stop the website
- Overwrite the files
- Start the website
That’s it. That’s all the major pieces. So let’s get as close to the stupidest, simplest process as we can. Here’s the call for that step, it’s a PowerShell script we pre-deploy on all build agents (with a build) that very rarely changes. We use the same set of scripts for all IIS website deployments, even the Jekyll-based blog. Here are the arguments we pass to the WebsiteDeploy.ps1 script:
-HAProxyServers "%deploy.HAProxy.Servers%"
-HAProxyPort %deploy.HAProxy.Port%
-Servers "%deploy.ServerNames%"
-Backends "%deploy.HAProxy.Backends%"
-Site "%deploy.WebsiteName%"
-Delay %deploy.HAProxy.Delay.IIS%
-DelayBetween %deploy.HAProxy.Delay.BetweenServers%
-WorkingDir "%teamcity.build.workingDir%\%deploy.WebsiteDirectory%"
-ExcludeFolders "%deploy.RoboCopy.ExcludedFolders%"
-ExcludeFiles "%deploy.RoboCopy.ExcludedFiles%"
-ContentSource "%teamcity.build.workingDir%\%deploy.contentSource%"
-ContentSStaticFolder "%deploy.contentSStaticFolder%"I’ve included script in the Gist here, with all the relevant functions from the profile included for completeness. The meat of the main script is here (lines shortened for fit below, but the complete version is in the Gist):
$ServerSession = Get-ServerSession $s
if ($ServerSession -ne $null)
{
Execute "Server: $s" {
HAProxyPost -Server $s -Action "drain"
# delay between taking a server out and killing the site, so current requests can finish
Delay -Delay $Delay
# kill website in IIS
ToggleSite -ServerSession $ServerSession -Action "stop" -Site $Site
# inform HAProxy this server is down, so we don't come back up immediately
HAProxyPost -Server $s -Action "hdown"
# robocopy!
CopyDirectory -Server $s -Source $WorkingDir -Destination "\\$s\..."
# restart website in IIS
ToggleSite -ServerSession $ServerSession -Action "start" -Site $Site
# stick the site back in HAProxy rotation
HAProxyPost -Server $s -Action "ready"
# session cleanup
$ServerSession | Remove-PSSession
}
}The steps here are the minimal needed to gracefully update a website, informing the load balancer of what’s happening and impacting users as little as possible. Here’s what happens:
- Tell HAProxy to stop sending new traffic
- Wait a few seconds for all current requests to finish
- Tell IIS to stop the site (
Stop-Website) - Tell HAProxy that this webserver is down (rather than waiting for it to detect)
- Copy the new code (
robocopy) - Tell IIS to start the new site (
Start-Website) - Tell HAProxy this website is ready to come back up
Note that HAProxy doesn’t immediately bring the site back online. It will do so after 3 successful polls, this is a key difference between MAINT and DRAIN in HAProxy. MAINT -> READY assumes the server is instantly up. DRAIN -> READY assumes down. The former has a very nasty effect on ThreadPool growth waiting with the initial slam while things are spinning up.
We repeat the above for all webservers in the build. There’s also a slight pause between each server, all of which is tunable with TeamCity settings.
Now the above is what happens for a single website. In reality, this step deploys twice. The reason why is race conditions. For the best client-side performance, our static assets have headers set to cache for 7 days. We break this cache only when it changes, not on every build. After all, you only need to fetch new CSS, SVGs, or JavaScript if they actually changed. Since cdn.sstatic.net comes from our web tier underneath, here’s what could happen due to the nature of a rolling build:
You hit ny-web01 and get a brand spanking new querystring for the new version. Your browser then hits our CDN at cdn.sstatic.net, which let’s say hits ny-web07…which has the old content. Oh crap, now we have old content cached with the new hash for a hell of a long time. That’s no good, that’s a hard reload to fix, after you purge the CDN. We avoid that by pre-deploying the static assets to another website in IIS specifically serving the CDN. This way sstatic.net gets the content in one rolling deploy, just before the new code issuing new hashes goes out. This means that there is a slight chance that someone will get new static content with an old hash (if they hit a CDN miss for a piece of content that actually changed this build). The big difference is that (rarely hit) problem fixes itself on a page reload, since the hash will change as soon as the new code is running a minute later. It’s a much better direction to fail in.
At the end of this step (in production), 7 of 9 web servers are typically online and serving users. The last 2 will finish their spin-up shortly after. The step takes about 2 minutes for 9 servers. But yay, our code is live! Now we’re free to deploy again for that bug we probably just sent out.
Step 9: New Strings Hook
This dev-only step isn’t particularly interesting, but useful. All it does is call a webhook telling it that some new strings were present in this build if there were any. The hook target triggers an upload to our translation service to tighten the iteration time on translations (similar to our chat mechanism above). It’s last because strictly speaking it’s optional and we don’t want it to interfere.
That’s it. Dev build complete. Put away the rolly chairs and swords.
Tiers
What we covered above was the entire development CI build with all the things™. All of the translation bits are development only because we just need to get the strings once. The meta and production builds are a simpler subset of the steps. Here’s a simple visualization that compares the build steps across tiers:
| Build Step | Dev | Meta | Prod |
|---|---|---|---|
| 1 - Migrate Sites DB | |||
| 2 - Migrate Q&A DBs | |||
| 3 - Find MoonSpeak Tools | |||
| 4 - Translation Dump (JavaScript) | |||
| 5 - MSBuild (Compile Compress and Minify) | |||
| 6 - Translation Dump (C#) | |||
| 7 - Translations Import English Strings | |||
| 8 - Deploy Website | |||
| 9 - New Strings Hook |
What do the tiers really translate to? All of our development sites are on WEB10 and WEB11 servers (under different application pools and websites). Meta runs on WEB10 and WEB11 servers, this is specifically meta.stackexchange.com and meta.stackoverflow.com. Production (all other Q&A sites and metas) like Stack Overflow are on WEB01-WEB09.
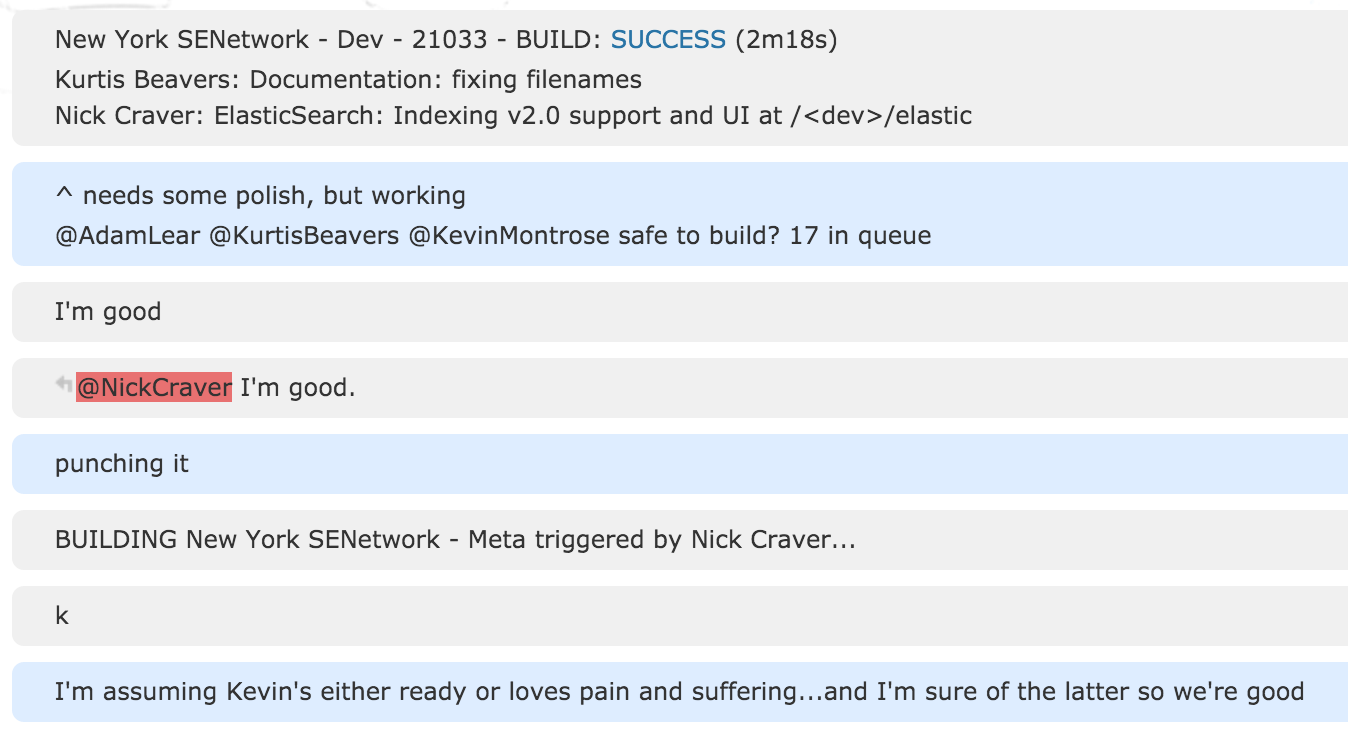
Note: we do a chat notification for build as someone goes through the tiers. Here’s me (against all sane judgement) building out some changes at 5:17pm on a Friday. Don’t try this at home, I’m a professional. Sometimes. Not often.
Database Migrations
See? I promised we’d come back to these. To reiterate: if new code is needed to handle the database migrations, it must be deployed first. In practice though, you’re likely dropping a table, or adding a table/column. For the removal case, we remove it from code, deploy, then deploy again (or later) with the drop migration. For the addition case, we would typically add it as nullable or unused in code. If it needs to be not null, a foreign key, etc. we’d do that in a later deploy as well.
The database migrator we use is a very simple repo we could open source, but honestly, there are dozens out there and the “same migration against n databases” is fairly specific. The others are probably much better and ours is very specific to only our needs. The migrator connects to the Sites database, gets the list of databases to run against, and executes all migrations against every one (running multiple databases in parallel). This is done by looking at the passed-in migrations folder and loading it (once) as well as hashing the contents of every file. Each database has a Migrations table that keeps track of what has already been run. It looks like this (descending order):
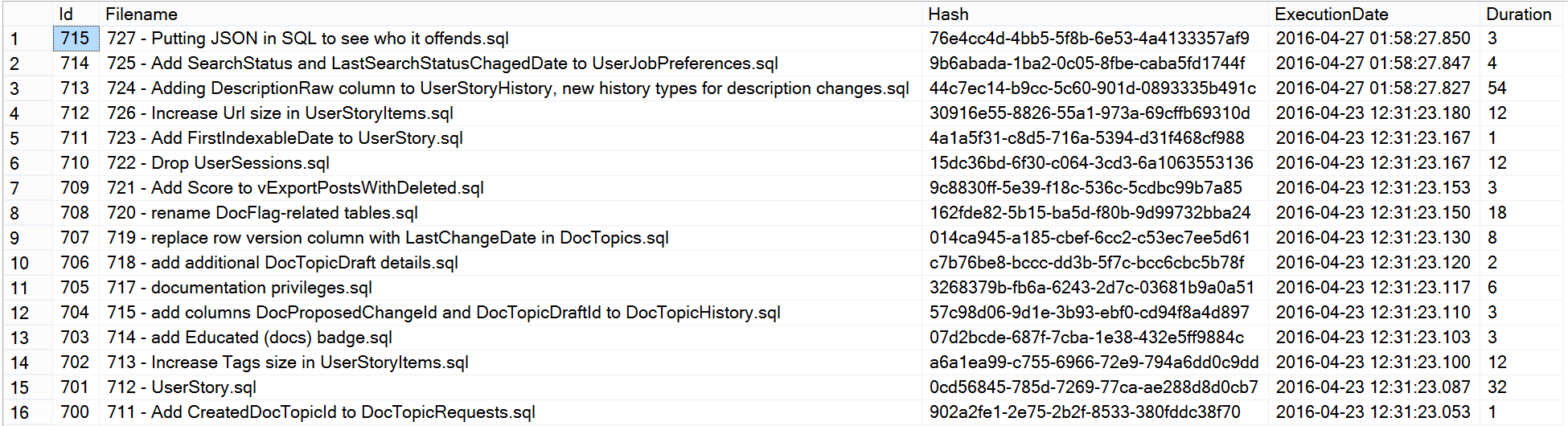
Note that the above aren’t all in file number order. That’s because 724 and 725 were in a branch for a few days. That’s not an issue, order is not guaranteed. Each migration itself is written to be idempotent, e.g. “don’t try to add the column if it’s already there”, but the specific order isn’t usually relevant. Either they’re all per-feature, or they’re actually going in-order anyway. The migrator respects the GO operator to separate batches and by default runs all migrations in a transaction. The transaction behavior can be changed with a first-line comment in the .sql file: -- no transaction --. Perhaps the most useful explanation to the migrator is the README.md I wrote for it. Here it is in the Gist.
In memory, we compare the list of migrations that already ran to those needing to run then execute what needs running, in file order. If we find the hash of a filename doesn’t match the migration with the same file name in the table, we abort as a safety measure. We can --force to resolve this in the rare cases a migration should have changed (almost always due to developer error). After all migrations have run, we’re done.
Rollbacks. We rarely do them. In fact, I can’t remember ever having done one. We avoid them through the approach in general: we deploy small and often. It’s often quicker to fix code and deploy than reverse a migration, especially across hundreds of databases. We also make development mimic production as often as possible, restoring production data periodically. If we needed to reverse something, we could just push another migration negating whatever we did that went boom. The tooling has no concept of rollback though. Why roll back when you can roll forward?
Localization/Translations (Moonspeak)
This will get its own post, but I wanted to hint at why we do all of this work at compile time. After all, I always advocate strongly for simplicity (yep, even in this 6,000-word blog post - the irony is not lost on me). You should only do something more complicated when you need to do something more complicated. This is one of those cases, for performance. Samo does a lot of work to make our localizations have as little runtime impact as possible. We’ll gladly trade a bit of build complexity to make that happen. While there are options such as .resx files or the new localization in ASP.NET Core 1.0, most of these allocate more than necessary especially with tokenized strings. Here’s what strings look like in our code:

And here’s what that line looks like compiled (via Reflector):
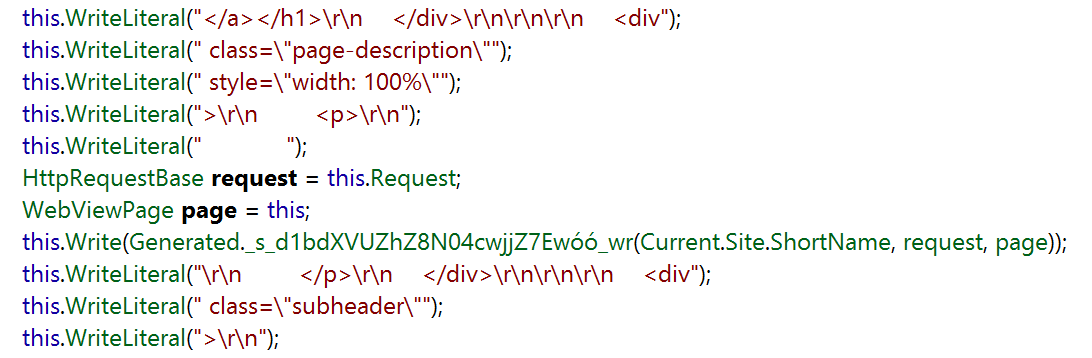
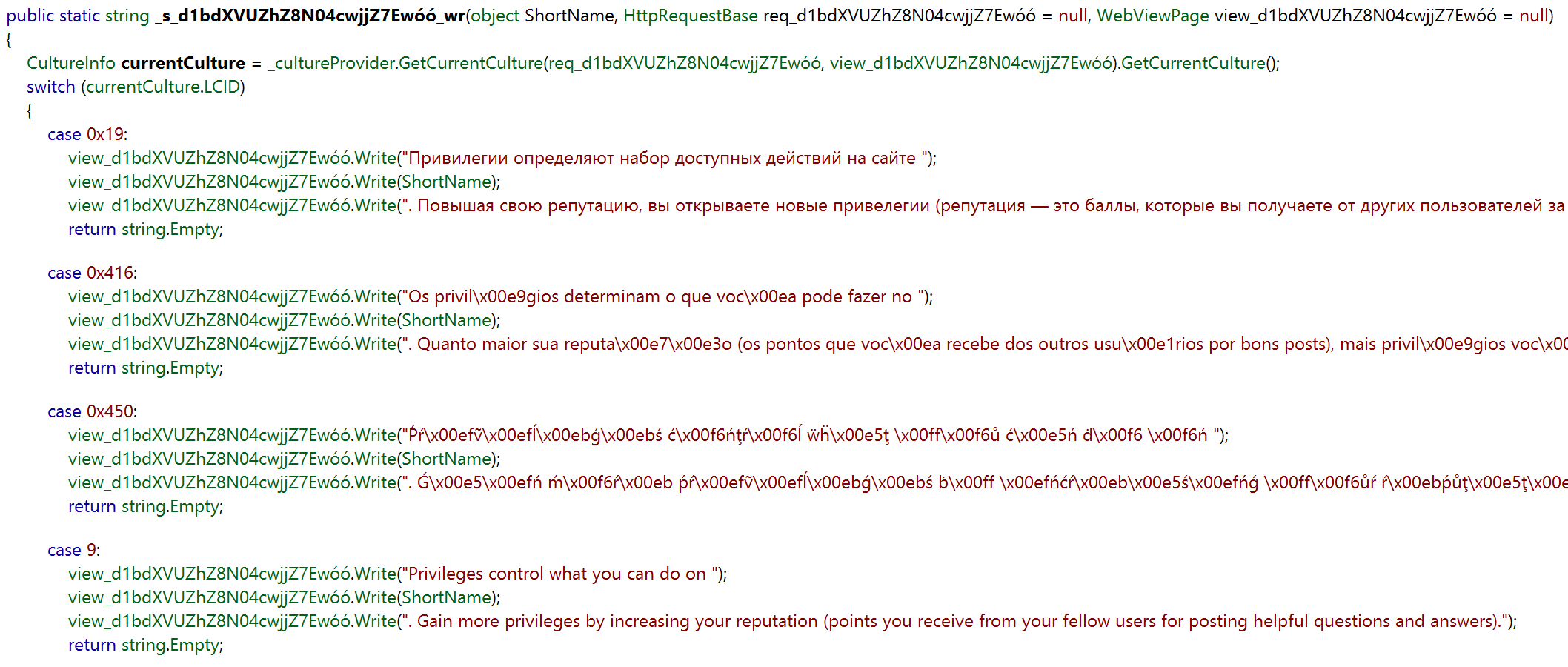
Note that we aren’t allocating the entire string together, only the pieces (with most interned). This may seem like a small thing, but at scale that’s a huge number of allocations and a lot of time in a garbage collector. I’m sure that just raises a ton of questions about how Moonspeak works. If so, go vote it up. It’s a big topic in itself, I only wanted to justify the compile-time complication it adds here. To us, it’s worth it.
Building Without Breaking
A question I’m often asked is how we prevent breaks while rolling out new code constantly. Here are some common things we run into and how we avoid them.
- Cache object changes:
- If we have a cache object that totally changes. That’s a new cache key and we let the old one fall out naturally with time.
- If we have a cache object that only changes locally (in-memory): nothing to do. The new app domain doesn’t collide.
- If we have a cache object that changes in redis, then we need to make sure the old and new protobuf signatures are compatible…or change the key.
- Tag Engine:
- The tag engine reloads on every build (currently). This is triggered by checking every minute for a new build hash on the web tier. If one is found, the application
\binand a few configs are downloaded to the Stack Server host process and spun up as a new app domain. This sidesteps the need for a deploy to those boxes and keeps local development setup simple (we run no separate process locally). - This one is changing drastically soon, since reloading every build is way more often that necessary. We’ll be moving to a more traditional deploy-it-when-it-changes model there soon. Possibly using GPUs. Stay tuned.
- The tag engine reloads on every build (currently). This is triggered by checking every minute for a new build hash on the web tier. If one is found, the application
- Renaming SQL objects:
- “Doctor it hurts when I do that!”
- “Don’t do that.”
- We may add and migrate, but a live rename is almost certain to cause an outage of some sort. We don’t do that outside of dev.
- APIs:
- Deploy the new endpoint before the new consumer.
- If changing an existing endpoint, it’s usually across 3 deploys: add (endpoint), migrate (consumer), cleanup (endpoint).
- Bugs:
- Try not to deploy bugs.
- If you screw up, try not to do it the same way twice.
- Accept that crap happens, live, learn, and move on.
That’s all of the major bits of our deployment process. But as always, ask any questions you have in comments below and you’ll get an answer.
I want to take a minute and thank the teams at Stack Overflow here. We build all of this, together. Many people help me review these blog posts before they go out to make sure everything is accurate. The posts are not short, and several people are reviewing them in off-hours because they simply saw a post in chat and wanted to help out. These same people hop into comment threads here, on Reddit, on Hacker News, and other places discussions pop up. They answer questions as they arise or relay them to someone who can answer. They do this on their own, out of a love for the community. I’m tremendously appreciative of their effort and it’s a privilege to work with some of the best programmers and sysadmins in the world. My lovely wife Elise also gives her time to help edit these before they go live. To all of you: thanks.
What’s next? The way this series works is I blog in order of what the community wants to know about most. Going by the Trello board, it looks like Monitoring is the next most interesting topic. So next time expect to learn how we monitor all of the systems here at Stack. I’ll cover how we monitor servers and services as well as the performance of Stack Overflow 24/7 as users see it all over the world. I’ll also cover many of the monitoring tools we’re using and have built; we’ve open sourced several big ones. Thanks for reading this post which ended up way longer than I envisioned and see you next time.